


![[体育新闻] 完整版20180423](https://yayyg.com/zb_users/upload/2024/02/202402061707199840387953.jpg)




补充一个ReID的strong baseline,用过的都说好https://github.com/michuanhaohao/reid-strong-baseline
[1] Luo, Hao, et al. "Bag of tricks and a strong baseline for deep person re-identification."Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. 2019.
[2] Luo, Hao, et al. "A Strong Baseline and Batch Normalization Neck for Deep Person Re-identification."arXiv preprint arXiv:1906.08332(2019).
补充一下AlignedReID开源的Pytorch版本代码:michuanhaohao/AlignedReID
[3] Luo, Hao, et al. "AlignedReID++: Dynamically matching local information for person re-identification."Pattern Recognition94 (2019): 53-61.
更新keras版本的reID代码和模型,代码没来得及整理,我自己也好久没用了,当个参考作用吧
https://github.com/michuanhaohao/keras_reid
git@github.com:michuanhaohao/keras_reid.git
包含classification和triplet loss, triplet hard loss
以及一个性能一般般的模型
============原回答==============
detection我没做过,reID的话要不八月份我在GitHub上开源我的基于tensorflow/keras复现identification loss/triplet loss/quadruplet loss版本的代码吧,到时候更新在这里,八月份前我暂不开源所以也不要私信我要代码了,一个原因是现在代码和屎一样乱,另外一个原因是因为参加一个reID的比赛,等到比赛结束之后再开源。其实 @郑哲东 总结的很好,他和郑良老师为reID贡献了很多文章,大家去骚扰他,哲东也开源了他们的代码,但是都是基于caffe实现的,所以我用keras复现了一下,但是实话实说相同的model我和哲东他们的performance一直差了10个点左右,可能data argumentation和手工艺调参上还是有tricks吧。
其实reID训练大体上就是基于四种loss,distance loss,identification loss,verification loss,attributes loss。
distance loss 是最常用的loss,就是用feature之间的距离来计算loss,同一个人的feature应该更近,不同人的feature要更远,那么用同一个人的距离减掉不同人的距离加上一个正常数和0取max实现,代表的有triplet loss,improved triplet loss,quadruplet loss,这些都可以直接搜到,quadruplet loss搜beyond triplet loss
identification loss就是classification loss,每一个人作为一个类别,来训练分类问题,把某个全连接层作为feature来做reID,一般identification loss能够很快收敛,但是面对百万级,千万级的数据稍显吃力
verification loss就是两张图来做二分类,判断是否为同一个人,这个作为辅助训练还行,作为主训练的loss估计要崩
attributes loss就是对于不同的属性做分类,比如上身颜色,是否戴帽子之类的,这个是有用的,但是标注数据太过奢侈,只有企业才能资本来标注可以使用的大量数据吧
===========================================paper=========================
论文的话我觉得补充一点点就好了,哲东已经把我大部分看过的论文都列出来了,另外SVDnet我复现了,只能说效果待考量,其实论文里面也就提高了一丢丢,我复现的结果压根就没有提高,可能我的姿势不对吧
quadruplet loss:a deep quadruplet network for person re-identification
估计相机间关系辅助reID:Pose-aware Multi-shot Matching for Improving Person Re-identification
对feature加了一层weights,感觉有很严重的overfitting问题:[1705.03332] Deep Person Re-Identification with Improved Embedding
基于video的reID:[1701.00193] Video-based Person Re-identification with Accumulative Motion Context
一篇光训练过程就可以写一篇论文的懵逼之作:[1611.05244] Deep Transfer Learning for Person Re-identification
郑良老师的综述:Past, Present and Future
慎入,过来人经验,这个研究方向本身就是伪科学,是从传统的图像检索发展过来的,最后还出了个号称超过人类性能的算法,真心觉得扯淡!其实reid 就是一群检索做不动的人,把目标缩小到person 这个特定的类,然后搞了一个小圈子,而且基本上全是中国人,发了一堆基本无用的文章,说它们无用肯定很多人厚着脸皮反击。那好吧,我就举个他们算法基本都是不work 的栗子吧,可以让他们候选检索的人换个不同颜色的衣服,如果赶时髦可以用GAN 生成一个,当然ID 还是同一个人(此处说不定又能灌一篇顶会),然后让他们的算法用query 检索,基本都傻逼!他们天天号称性能高就可以用于安全领域,其实最简单的小偷偷完东西换件衣服这样简单的方式,现在的算法都基本上会被骗过,可想而知这好方向有多不靠谱!窃以为,reid 做个签到,门禁系统估计还有戏!可是失望的是,现在他们的算法连在黑天和白天出现的同一个人都傻傻分不清,你还能指望他们干什么?如说的不对,欢迎打脸!
完整的end-to-end的系统比较复杂,不过把行人检测与再识别结合到一起我觉得应该算是一个比较有前途的方向,至少feature可以重复利用。CVPR17上CUHK Tong Xiao的工作算是一个比较典型的解决方案(Joint Detection and Identification Feature Learning for Person Search)。
单独说行人再识别的部分,我们最近刚刚release了 benchmark paper 的code: https://github.com/RSL-NEU/person-reid-benchmark 里面包含了大部分基于传统pipeline的feature和metric learning的源码,single shot和multi shot都有。目前数据库支持有限,后续还会不断更新和完善,也欢迎大家多提意见多开issue 。
感觉目前行人重识别领域非常不友好,做的人太多了,导致领域内竞争非常大。
现在一些会议和期刊,对ReID文章可以说是吹毛求疵,很多reviewer明显都是奔着拒稿的目的才进行审稿的。而对一些大组,一些很简单的idea很naive的文章也很容易就中顶会,让人摸不着头脑。
现在最好能跑就跑,不要再做ReID了。
【行为识别】保护隐私和效用的传感器数据转换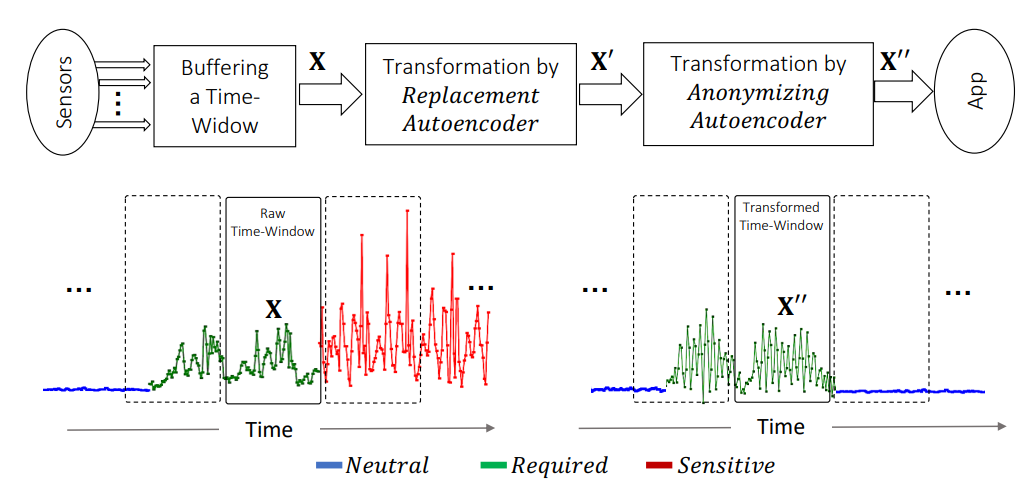
作者:Mohammad Malekzadeh, Richard G. Clegg, Andrea Cavallaro, Hamed Haddadi
链接:
https://arxiv.org/abs/1911.05996v1
代码:
https://github.com/mmalekzadeh/motion-sense
英文摘要:
Sensitive inferences and user re-identification are major threats to privacy when raw sensor data from wearable or portable devices are shared with cloud-assisted applications. To mitigate these threats, we propose mechanisms to transform sensor data before sharing them with applications running on users' devices. These transformations aim at eliminating patterns that can be used for user re-identification or for inferring potentially sensitive activities, while introducing a minor utility loss for the target application (or task). We show that, on gesture and activity recognition tasks, we can prevent inference of potentially sensitive activities while keeping the reduction in recognition accuracy of non-sensitive activities to less than 5 percentage points. We also show that we can reduce the accuracy of user re-identification and of the potential inference of gender to the level of a random guess, while keeping the accuracy of activity recognition comparable to that obtained on the original data.
中文摘要:
当来自可穿戴或便携式设备的原始传感器数据与云辅助应用程序共享时,敏感推断和用户重新识别是隐私的主要威胁。为了减轻这些威胁,我们提出了在与用户设备上运行的应用程序共享传感器数据之前转换传感器数据的机制。这些转换旨在消除可用于用户重新识别或推断潜在敏感活动的模式,同时为目标应用程序(或任务)引入较小的效用损失。我们表明,在手势和活动识别任务中,我们可以防止推断潜在的敏感活动,同时将非敏感活动的识别准确度降低到5个百分点以下。我们还表明,我们可以将用户重新识别和潜在性别推断的准确性降低到随机猜测的水平,同时保持活动识别的准确性与在原始数据上获得的准确性相当。
【行为识别】移动传感器数据匿名化
作者:Mohammad Malekzadeh, Richard G. Clegg, Andrea Cavallaro, Hamed Haddadi
链接:
https://arxiv.org/abs/1810.11546v3
代码:
https://github.com/mmalekzadeh/motion-sense
英文摘要:
Motion sensors such as accelerometers and gyroscopes measure the instant acceleration and rotation of a device, in three dimensions. Raw data streams from motion sensors embedded in portable and wearable devices may reveal private information about users without their awareness. For example, motion data might disclose the weight or gender of a user, or enable their re-identification. To address this problem, we propose an on-device transformation of sensor data to be shared for specific applications, such as monitoring selected daily activities, without revealing information that enables user identification. We formulate the anonymization problem using an information-theoretic approach and propose a new multi-objective loss function for training deep autoencoders. This loss function helps minimizing user-identity information as well as data distortion to preserve the application-specific utility. The training process regulates the encoder to disregard user-identifiable patterns and tunes the decoder to shape the output independently of users in the training set. The trained autoencoder can be deployed on a mobile or wearable device to anonymize sensor data even for users who are not included in the training dataset. Data from 24 users transformed by the proposed anonymizing autoencoder lead to a promising trade-off between utility and privacy, with an accuracy for activity recognition above 92% and an accuracy for user identification below 7%.
中文摘要:
加速度计和陀螺仪等运动传感器在三个维度上测量设备的瞬时加速度和旋转。来自嵌入在便携式和可穿戴设备中的运动传感器的原始数据流可能会在用户不知情的情况下泄露有关用户的私人信息。例如,运动数据可能会披露用户的体重或性别,或者启用他们的重新识别。为了解决这个问题,我们提出了一种传感器数据的设备上转换,以供特定应用程序共享,例如监控选定的日常活动,而不会泄露能够识别用户的信息。我们使用信息理论方法制定了匿名化问题,并提出了一种新的多目标损失函数来训练深度自动编码器。此损失函数有助于最大限度地减少用户身份信息和数据失真,以保留特定于应用程序的实用程序。训练过程调节编码器以忽略用户可识别的模式,并调整解码器以独立于训练集中的用户塑造输出。经过训练的自动编码器可以部署在移动或可穿戴设备上,即使对于未包含在训练数据集中的用户,传感器数据也可以匿名化。来自24个用户的数据由提议的匿名自动编码器转换,在效用和隐私之间取得了有希望的权衡,活动识别的准确度高于92%,用户识别的准确度低于7%。
【行为识别】保护感官数据免受敏感推断的影响
作者:Mohammad Malekzadeh, Richard G. Clegg, Andrea Cavallaro, Hamed Haddadi
链接:
https://arxiv.org/abs/1802.07802v4
代码:
https://github.com/mmalekzadeh/motion-sense
英文摘要:
There is growing concern about how personal data are used when users grant applications direct access to the sensors of their mobile devices. In fact, high resolution temporal data generated by motion sensors reflect directly the activities of a user and indirectly physical and demographic attributes. In this paper, we propose a feature learning architecture for mobile devices that provides flexible and negotiable privacy-preserving sensor data transmission by appropriately transforming raw sensor data. The objective is to move from the current binary setting of granting or not permission to an application, toward a model that allows users to grant each application permission over a limited range of inferences according to the provided services. The internal structure of each component of the proposed architecture can be flexibly changed and the trade-off between privacy and utility can be negotiated between the constraints of the user and the underlying application. We validated the proposed architecture in an activity recognition application using two real-world datasets, with the objective of recognizing an activity without disclosing gender as an example of private information. Results show that the proposed framework maintains the usefulness of the transformed data for activity recognition, with an average loss of only around three percentage points, while reducing the possibility of gender classification to around 50\%, the target random guess, from more than 90\% when using raw sensor data. We also present and distribute MotionSense, a new dataset for activity and attribute recognition collected from motion sensors.
中文摘要:
当用户授权应用程序直接访问其移动设备的传感器时,人们越来越担心个人数据的使用方式。事实上,运动传感器生成的高分辨率时间数据直接反映了用户的活动,间接反映了物理和人口统计属性。在本文中,我们为移动设备提出了一种特征学习架构,该架构通过适当地转换原始传感器数据来提供灵活且可协商的隐私保护传感器数据传输。目标是从当前授予或不授予应用程序权限的二进制设置转变为允许用户根据提供的服务在有限的推理范围内授予每个应用程序权限的模型。所提出架构的每个组件的内部结构可以灵活改变,隐私和效用之间的权衡可以在用户和底层应用程序的约束之间进行协商。我们使用两个真实世界的数据集在活动识别应用程序中验证了提议的架构,目的是在不公开性别作为隐私信息示例的情况下识别活动。结果表明,所提出的框架保持了转换后的数据对活动识别的有用性,平均损失仅约3个百分点,同时将性别分类的可能性从90以上降低到50%左右,即目标随机猜测\%使用原始传感器数据时。我们还展示并分发了MotionSense,这是一个从运动传感器收集的用于活动和属性识别的新数据集。
【行为识别】视频中的对象级视觉推理
作者:Fabien Baradel, Natalia Neverova, Christian Wolf, Julien Mille, Greg Mori
链接:
https://arxiv.org/abs/1806.06157v3
代码:
https://github.com/fabienbaradel/object_level_visual_reasoning
英文摘要:
Human activity recognition is typically addressed by detecting key concepts like global and local motion, features related to object classes present in the scene, as well as features related to the global context. The next open challenges in activity recognition require a level of understanding that pushes beyond this and call for models with capabilities for fine distinction and detailed comprehension of interactions between actors and objects in a scene. We propose a model capable of learning to reason about semantically meaningful spatiotemporal interactions in videos. The key to our approach is a choice of performing this reasoning at the object level through the integration of state of the art object detection networks. This allows the model to learn detailed spatial interactions that exist at a semantic, object-interaction relevant level. We evaluate our method on three standard datasets (Twenty-BN Something-Something, VLOG and EPIC Kitchens) and achieve state of the art results on all of them. Finally, we show visualizations of the interactions learned by the model, which illustrate object classes and their interactions corresponding to different activity classes.
中文摘要:
人类活动识别通常通过检测关键概念(例如全局和局部运动、与场景中存在的对象类相关的特征以及与全局上下文相关的特征)来解决。活动识别中的下一个开放挑战需要一定程度的理解,并要求模型具有精细区分和详细理解场景中演员和对象之间交互的能力。我们提出了一种能够学习推理视频中语义上有意义的时空交互的模型。我们方法的关键是选择通过集成最先进的对象检测网络在对象级别执行此推理。这允许模型学习存在于语义、对象交互相关级别的详细空间交互。我们在三个标准数据集(Twenty-BN Something-Something、VLOG和EPIC Kitchens)上评估了我们的方法,并在所有这些数据集上取得了最先进的结果。最后,我们展示了模型学习到的交互的可视化,它说明了对象类及其对应于不同活动类的交互。
【行为识别】Eidetic 3D LSTM:视频预测及其他模型
作者:Yunbo Wang, Lu Jiang, Ming-Hsuan Yang, Li-Jia Li, Mingsheng Long, Li Fei-Fei
链接:
https://openreview.net/forum?id=B1lKS2AqtX
代码:
https://github.com/metrofun/E3D-LSTM
https://github.com/google/e3d_lstm
英文摘要:
Spatiotemporal predictive learning, though long considered to be a promising self-supervised feature learning method, seldom shows its effectiveness beyond future video prediction. The reason is that it is difficult to learn good representations for both short-term frame dependency and long-term high-level relations. We present a new model, Eidetic 3D LSTM (E3D-LSTM), that integrates 3D convolutions into RNNs. The encapsulated 3D-Conv makes local perceptrons of RNNs motion-aware and enables the memory cell to store better short-term features. For long-term relations, we make the present memory state interact with its historical records via a gate-controlled self-attention module. We describe this memory transition mechanism eidetic as it is able to effectively recall the stored memories across multiple time stamps even after long periods of disturbance. We first evaluate the E3D-LSTM network on widely-used future video prediction datasets and achieve the state-of-the-art performance. Then we show that the E3D-LSTM network also performs well on the early activity recognition to infer what is happening or what will happen after observing only limited frames of video. This task aligns well with video prediction in modeling action intentions and tendency.
中文摘要:
时空预测学习虽然长期以来被认为是一种很有前途的自监督特征学习方法,但在未来视频预测之外很少显示其有效性。原因是很难为短期框架依赖和长期高层关系学习良好的表示。我们提出了一种新模型Eidetic 3D LSTM(E3D-LSTM),它将3D卷积集成到RNN中。封装的3D-Conv使RNN的局部感知器具有运动感知能力,并使存储单元能够存储更好的短期特征。对于长期关系,我们通过门控自注意力模块使当前记忆状态与其历史记录交互。我们描述了这种记忆转换机制的特点,因为即使在长时间干扰之后,它也能够有效地调用跨多个时间戳的存储记忆。我们首先在广泛使用的未来视频预测数据集上评估E3D-LSTM网络并实现最先进的性能。然后我们展示了E3D-LSTM网络在早期活动识别上也表现良好,可以在仅观察有限的视频帧后推断正在发生的事情或将发生的事情。该任务与建模动作意图和趋势的视频预测非常吻合。
AI&R是人工智能与机器人垂直领域的综合信息平台。我们的愿景是成为通往AGI(通用人工智能)的高速公路,连接人与人、人与信息,信息与信息,让人工智能与机器人没有门槛。
欢迎各位AI与机器人爱好者关注我们,每天给你有深度的内容。
微信搜索公众号【AIandR艾尔】关注我们,获取更多资源❤biubiubiu~
【自动驾驶】用于点云 3D 对象检测的类平衡分组和采样
作者:Benjin Zhu, Zhengkai Jiang, Xiangxin Zhou, Zeming Li, Gang Yu
链接:
https://arxiv.org/abs/1908.09492v1
代码:
https://github.com/poodarchu/Det3D
https://github.com/poodarchu/Class-balanced-Grouping-and-Sampling-for-Point-Cloud-3D-Object-Detection
英文摘要:
This report presents our method which wins the nuScenes3D Detection Challenge [17] held in Workshop on Autonomous Driving(WAD, CVPR 2019). Generally, we utilize sparse 3D convolution to extract rich semantic features, which are then fed into a class-balanced multi-head network to perform 3D object detection. To handle the severe class imbalance problem inherent in the autonomous driving scenarios, we design a class-balanced sampling and augmentation strategy to generate a more balanced data distribution. Furthermore, we propose a balanced group-ing head to boost the performance for the categories withsimilar shapes. Based on the Challenge results, our methodoutperforms the PointPillars [14] baseline by a large mar-gin across all metrics, achieving state-of-the-art detection performance on the nuScenes dataset. Code will be released at CBGS.
中文摘要:
本报告介绍了我们的方法,该方法赢得了在自动驾驶研讨会(WAD,CVPR2019)举行的nuScenes3D检测挑战赛[17]。通常,我们利用稀疏3D卷积来提取丰富的语义特征,然后将其输入到类平衡多头网络中以执行3D对象检测。为了处理自动驾驶场景中固有的严重类别不平衡问题,我们设计了一种类别平衡的采样和增强策略,以生成更平衡的数据分布。此外,我们提出了一个平衡的分组头来提高具有相似形状的类别的性能。根据挑战赛的结果,我们的方法在所有指标上都比PointPillars[14]基线有很大的优势,在nuScenes数据集上实现了最先进的检测性能。代码将在CBGS发布。
【自动驾驶】基于切片的学习:关键数据切片中残差学习的编程模型
作者:Vincent S. Chen, Sen Wu, Zhenzhen Weng, Alexander Ratner, Christopher Ré
链接:
https://arxiv.org/abs/1909.06349v2
代码:
https://github.com/snorkel-team/snorkel-tutorials
英文摘要:
In real-world machine learning applications, data subsets correspond to especially critical outcomes: vulnerable cyclist detections are safety-critical in an autonomous driving task, and "question" sentences might be important to a dialogue agent's language understanding for product purposes. While machine learning models can achieve high quality performance on coarse-grained metrics like F1-score and overall accuracy, they may underperform on critical subsets---we define these as slices, the key abstraction in our approach. To address slice-level performance, practitioners often train separate "expert" models on slice subsets or use multi-task hard parameter sharing. We propose Slice-based Learning, a new programming model in which the slicing function (SF), a programming interface, specifies critical data subsets for which the model should commit additional capacity. Any model can leverage SFs to learn slice expert representations, which are combined with an attention mechanism to make slice-aware predictions. We show that our approach maintains a parameter-efficient representation while improving over baselines by up to 19.0 F1 on slices and 4.6 F1 overall on datasets spanning language understanding (e.g. SuperGLUE), computer vision, and production-scale industrial systems.
中文摘要:
在现实世界的机器学习应用程序中,数据子集对应于特别关键的结果:易受攻击的骑车人检测在自动驾驶任务中对安全至关重要,而“问题”句子对于对话代理的语言理解对于产品目的可能很重要。虽然机器学习模型可以在F1分数和整体准确度等粗粒度指标上实现高质量性能,但它们可能在关键子集上表现不佳——我们将这些定义为切片,这是我们方法中的关键抽象。为了解决切片级别的性能,从业者通常在切片子集上训练单独的“专家”模型或使用多任务硬参数共享。我们提出了基于切片的学习,这是一种新的编程模型,其中切片功能(SF),一种编程接口,指定模型应为其提供额外容量的关键数据子集。任何模型都可以利用SF来学习切片专家表示,并结合注意力机制进行切片感知预测。我们表明,我们的方法保持了参数有效的表示,同时在跨越语言理解(例如SuperGLUE)、计算机视觉和生产规模工业系统的数据集上将切片上的F1提高了19.0F1和总体上提高了4.6F1。
【自动驾驶】SegMap:使用数据驱动描述符的基于段的映射和定位
作者:Renaud Dubé, Andrei Cramariuc, Daniel Dugas, Hannes Sommer, Marcin Dymczyk, Juan Nieto, Roland Siegwart, Cesar Cadena
链接:
https://arxiv.org/abs/1909.12837v1
代码:
https://github.com/ethz-asl/segmap
英文摘要:
Precisely estimating a robot's pose in a prior, global map is a fundamental capability for mobile robotics, e.g. autonomous driving or exploration in disaster zones. This task, however, remains challenging in unstructured, dynamic environments, where local features are not discriminative enough and global scene descriptors only provide coarse information. We therefore present SegMap: a map representation solution for localization and mapping based on the extraction of segments in 3D point clouds. Working at the level of segments offers increased invariance to view-point and local structural changes, and facilitates real-time processing of large-scale 3D data. SegMap exploits a single compact data-driven descriptor for performing multiple tasks: global localization, 3D dense map reconstruction, and semantic information extraction. The performance of SegMap is evaluated in multiple urban driving and search and rescue experiments. We show that the learned SegMap descriptor has superior segment retrieval capabilities, compared to state-of-the-art handcrafted descriptors. In consequence, we achieve a higher localization accuracy and a 6% increase in recall over state-of-the-art. These segment-based localizations allow us to reduce the open-loop odometry drift by up to 50%. SegMap is open-source available along with easy to run demonstrations.
中文摘要:
在先前的全局地图中精确估计机器人的姿势是移动机器人的基本能力,例如在灾区进行自动驾驶或探索。然而,这项任务在非结构化、动态环境中仍然具有挑战性,在这些环境中,局部特征的判别力不够,全局场景描述符只能提供粗略的信息。因此,我们提出了SegMap:一种基于3D点云中段提取的定位和映射的地图表示解决方案。在片段级别上工作可提高视点和局部结构变化的不变性,并促进大规模3D数据的实时处理。SegMap利用单个紧凑的数据驱动描述符来执行多个任务:全局定位、3D密集地图重建和语义信息提取。在多个城市驾驶和搜救实验中评估了SegMap的性能。我们表明,与最先进的手工描述符相比,学习的SegMap描述符具有出色的段检索能力。因此,我们实现了更高的定位精度,并且召回率比现有技术提高了6%。这些基于分段的定位使我们能够将开环里程计漂移减少多达50%。SegMap是开源的,并且易于运行演示。
【自动驾驶】PIE:行人意图估计和轨迹预测的大规模数据集和模型
作者:Amir Rasouli, Iuliia Kotseruba, Toni Kunic, John K大佬们都在玩{精选官网网址: www.vip333.Co }值得信任的品牌平台!. Tsotsos;
链接:
http://openaccess.thecvf.com/content_ICCV_2019/html/Rasouli_PIE_A_Large-Scale_Dataset_and_Models_for_Pedestrian_Intention_Estimation_ICCV_2019_paper.html
代码:
https://github.com/aras62/PIEPredict
英文摘要:
Pedestrian behavior anticipation is a key challenge in the design of assistive and autonomous driving systems suitable for urban environments. An intelligent system should be able to understand the intentions or underlying motives of pedestrians and to predict their forthcoming actions. To date, only a few public datasets were proposed for the purpose of studying pedestrian behavior prediction in the context of intelligent driving. To this end, we propose a novel large-scale dataset designed for pedestrian intention estimation (PIE). We conducted a large-scale human experiment to establish human reference data for pedestrian intention in traffic scenes. We propose models for estimating pedestrian crossing intention and predicting their future trajectory. Our intention estimation model achieves 79% accuracy and our trajectory prediction algorithm outperforms state-of-the-art by 26% on the proposed dataset. We further show that combining pedestrian intention with observed motion improves trajectory prediction. The dataset and models are available at http://data.nvision2.eecs.yorku.ca/PIE_dataset/.
中文摘要:
行人行为预测是设计适用于城市环境的辅助和自动驾驶系统的关键挑战。智能系统应该能够理解行人的意图或潜在动机,并预测他们即将采取的行动。迄今为止,仅提出了少数公共数据集用于研究智能驾驶背景下的行人行为预测。为此,我们提出了一种为行人意图估计(PIE)设计的新型大规模数据集。我们进行了大规模的人体实验,以建立交通场景中行人意图的人体参考数据。我们提出了用于估计行人过街意图并预测其未来轨迹的模型。我们的意图估计模型达到了79%的准确率,并且我们的轨迹预测算法在所提出的数据集上比最先进的算法高出26%。我们进一步表明,将行人意图与观察到的运动相结合可以改善轨迹预测。数据集和模型可在http://data.nvision2.eecs.yorku.ca/PIE_dataset/获得。
【自动驾驶】在端到端自动驾驶模型中攻击基于视觉的感知
作者:Adith Boloor, Karthik Garimella, Xin He, Christopher Gill, Yevgeniy Vorobeychik, Xuan Zhang
链接:
https://arxiv.org/abs/1910.01907v1
代码:
https://github.com/xz-group/AdverseDrive
英文摘要:
Recent advances in machine learning, especially techniques such as deep neural networks, are enabling a range of emerging applications. One such example is autonomous driving, which often relies on deep learning for perception. However, deep learning-based perception has been shown to be vulnerable to a host of subtle adversarial manipulations of images. Nevertheless, the vast majority of such demonstrations focus on perception that is disembodied from end-to-end control. We present novel end-to-end attacks on autonomous driving in simulation, using simple physically realizable attacks: the painting of black lines on the road. These attacks target deep neural network models for end-to-end autonomous driving control. A systematic investigation shows that such attacks are easy to engineer, and we describe scenarios (e.g., right turns) in which they are highly effective. We define several objective functions that quantify the success of an attack and develop techniques based on Bayesian Optimization to efficiently traverse the search space of higher dimensional attacks. Additionally, we define a novel class of hijacking attacks, where painted lines on the road cause the driver-less car to follow a target path. Through the use of network deconvolution, we provide insights into the successful attacks, which appear to work by mimicking activations of entirely different scenarios.
中文摘要:
机器学习的最新进展,特别是深度神经网络等技术,正在推动一系列新兴应用。一个这样的例子是自动驾驶,它通常依赖于深度学习来进行感知。然而,基于深度学习的感知已被证明容易受到一系列微妙的图像对抗性操作的影响。然而,绝大多数此类演示都集中在脱离端到端控制的感知上。我们使用简单的物理可实现攻击:在道路上绘制黑线,在模拟中提出了对自动驾驶的新颖的端到端攻击。这些攻击针对端到端自动驾驶控制的深度神经网络模型。系统调查表明,此类攻击很容易设计,我们描述了它们非常有效的场景(例如,右转)。我们定义了几个量化攻击成功的目标函数,并开发了基于贝叶斯优化的技术,以有效地遍历高维攻击的搜索空间。此外,我们定义了一类新的劫持攻击,其中道路上的画线导致无人驾驶汽车跟随目标路径。通过使用网络反卷积,我们提供了对成功攻击的见解,这些攻击似乎通过模仿完全不同场景的激活来起作用。
AI&R是人工智能与机器人垂直领域的综合信息平台。我们的愿景是成为通往AGI(通用人工智能)的高速公路,连接人与人、人与信息,信息与信息,让人工智能与机器人没有门槛。
欢迎各位AI与机器人爱好者关注我们,每天给你有深度的内容。
微信搜索公众号【AIandR艾尔】关注我们,获取更多资源❤biubiubiu~
PETA 数据集。该数据集有 19000 张行人图像,其中也包含了同一行人处于不同姿态时的图像。该数据集的行人图像的分辨率最小为 17×39 像素,分辨率最大为 169×365 像素。其中一共含有 8705 个人,每个行人都被标注为 61 个二进制数和 4 个多类别属性。将该 19000 张图像随机划分为三部分,一部分用于训练集包含 9500 个图像,一部分用于验证集包含 1900 个图像,一部分用于测试包含 7600个图像。另外该数据集有一个限制,对于同一个行人存在多个不同视角的图像,而行人的属性在同一个行人中是共享的,例如有的图像中某些属性不可见也会被标注出来。但该方法对于视觉感知来说不算十分合理,如下图(a)所示。除了图像中包含一个人外,有的图像中包含多个行人,如下图(b)所示。
RAP 数据集。如下图所示,该数据集共包含 41585 张图像,图像分辨率大小在36x92至344x554像素。该数据集中一部分用于训练包含 33268 张图像,剩余的图像用于测试。每个图像包含 72 个细粒度属性。有三个环境和上下文相关的因素被显示的注释,分别为视点、遮挡样式和主体部分。在标注属性时主要考虑了下面六个部分:全身属性、姿势动作、遮挡、附件、时空信息和部件属性。表 1表示了 RAP 数据集的标注信息。 基于深度学习实例分割算法研究现状
我也是 马上开题了 但是不知道该咋弄 这个方向
行人重识别研究最早起源于二十世纪九十年代中期,研究者们借鉴、引入了一些图像处理、模式识别领域的成熟方法,侧重研究了行人的可用特征、简单分类算法。自 2014 年以来,行人重识别技术的训练库趋于大规模化,广泛采用深度学习框架。随着高校、研究所以及一些厂商的研究持续深入,行人重识别技术得到了飞速的发展。下面介绍几种基于深度学习的行人重识别方法:
(1)基于表征学习的行人重识别。这种方法比较常见。CNN 提取图像的表征特征,这就可以把行人重拾别问题转换成分类和验证问题,在制作数据集时将行人 ID 标注清楚,然后进行训练模型,重识别则靠网络验证两张行人图像来实现。
(2) 基于度量学习的行人重识别。与基于表征学习的行人重识别不同,基于度量学习则是把重识别的实现放在对行人图像相似度比较上,也就是说对于同一行人的图片,他们之间相似度要更大,损失函数也是根据这种关系进行设计,比如三元组损失、四元组损失等。
(3) 基于局部特征的行人重识别,很长一段时间,行人重识别对于特征提取都是关注一整张图,但随着时间的推移,全局特征逐渐不满足研究需求,于是局部特征被大家关注,通过对图像处理进行提取局部特征进行行人重识别研究。
(4) 基于视频序列的行人重识别,采用视频序列的目的是获取更多信息,不仅仅依靠图像中包含的行人信息,还可以依靠整个序列中行人的状态以及运动行为信息,在提取单帧行人图像特征的同时,还会通过递归循环网络(Recurrent neural networks,RNN)提取行人时序特征。
目前行人识别还存在一些挑战,比如不同摄像头道人行人外观产生变化、目标遮挡导致行人特征损失、不同行人衣服颜色近似导致区分度降低。想要解决这些问题主要从两大方向,一是从特征提取角度,学习能够应对在不同摄像头下行人变化的特征,二是从度量学习角度,将学习到的特征映射到性的空间视像头的人更近,不同的人更远。
海外主要的行人重识别系统的研究机构有悉尼科技大学、伦敦玛丽女王大学等;中国主要有清华大学、北京大学、复旦大学、香港中文大学、西安交通大学、中国科学技术大学、中山大学,中科院自动化所等。2020 年,在行人重识别方面,依图科技刷新在多个数据集上的最好成绩,极大拓展了算法和应用的边界 ,加速行人重识别大规模商业化落地。
行人重识别简介

语言引导的人称搜索的关键是在视觉输入和文本输入之间建立跨模态关联。现有方法侧重于设计多模态注意机制和新的跨模态损失函数来隐式学习这种关联。作者提出了一种基于颜色推理(LapsCore)的语言引导人搜索表示学习方法。它可以明确地双向建立细粒度跨模态关联。具体来说,设计了一对双子任务,图像着色和文本完成。在前一个任务中,学习富文本信息以对灰度图像进行着色,后一个任务要求模型理解图像并完成标题中的彩色文字空缺。这两个子任务使模型能够学习文本短语和图像区域之间的正确对齐,从而可以学习丰富的多模态表示。在多个数据集上的大量实验证明了该方法的有效性和优越性。
LapsCore: Language-guided Person Search via Color Reasoning
论文地址:https://ieeexplore.ieee.org/document/9711140/
代码地址:未开源
语言引导的人搜索在智能监控中有着广阔的应用前景,因此引起了人们的广泛关注。如上图所示,它旨在从与自然语言描述查询最匹配的大型图像数据库中检索人物。与基于图像和基于属性的person ReID相比,语言查询比图像查询更容易获得,并且提供了比属性更全面和准确的描述。
在语言引导的人员搜索任务中存在两个主要挑战。首先,由于跨模态间隙,很难计算视觉文本的真实性并构建图像-文本对齐。其次,人员搜索是一项细粒度的检索任务:(1)文本为目标人提供非常详细的描述;(2)人物形象在外观上存在明显的跨类差异。
在语言引导人搜索的开创性工作之后,人们投入了大量精力来应对这项任务的挑战。一些工作设计高级模型,学习更好的图像和文本表示。另一些工作中开发了注意力机制,以建立局部图像-文本关联。还有一些工作提出了新的损失函数来缩小视觉和文本特征之间的距离。然而,所有这些方法都隐含地学习了跨模态局部关联,这对模型的学习能力留下了严格的测试。从大量的语言引导人搜索实验中,作者观察到颜色在检索中起着重要作用。面对个人图像,人类倾向于接受视觉颜色来提取外观信息,然后理解与这些颜色相关的衣服或装饰品。因此,作者受到启发,提出了一种新的表示学习方法LapsCore,通过求解颜色推理子任务,引导模型明确学习细粒度跨模态关联。
如上图所示,第一个子任务,文本引导图像着色(IC),是根据其文本描述对灰度图像进行着色。在该任务中,模型能够正确探测文本中丰富的颜色信息,并将其与相应的图像区域对齐。例如,在上图中,不仅需要提取单词“red”,还需要将“shirt”的语义与“red”配对,并且图像中表示“shirt”的空间区域应为红色。因此,可以构造文本到图像的局部关联。对于相反方向的图像到文本,设计了另一个子任务图像引导文本完成(TC)。具体来说,在每个描述句子中,删除所有颜色词,这些空缺需要利用成对的彩色图像来完成。这样,有效的图像区域可以显著地表示,然后与相关的文本短语相关联。虽然颜色推理任务对于人类来说并不复杂,但它们需要模型的全面跨模态理解来解决。通过使用这两个子任务,可以在主任务图像文本匹配中利用更好的多模态表示。此外,作者提出了另一个“颜色”推理子任务,旨在使用字幕完成缺失通道的图像特征,该任务将IC任务从图像颜色通道完成推广到特征语义通道完成。给定输入图像的特征表示,作者部分屏蔽了一些通道,并使用标题来恢复它们。在此过程中,可以探测和利用包括颜色在内的一般文本信息。因此,在颜色不是标题中的主要信息的情况下,它赋予了本文的方法鲁棒性。
为了解决第一个子任务IC,作者将其转化为像素回归问题。将原始图像处理为灰度图像作为输入,并使用成对字幕恢复原始图像。TC任务可以被视为视觉问答问题,其中问题是一个带有颜色词空缺的句子,答案是候选颜色之一。在图像特征通道完成子任务中,作者首先在个人ID分类任务上预训练特征提取器,然后屏蔽视觉特征图,以便使用字幕进行恢复。作者在语言指导的人员搜索数据集cuhk-pedes上进行了广泛的实验。实验证明,该方法可以显著提高性能。对通用图像文本检索数据集的验证也证实了其有效性,包括加州理工大学UCSD Birds、Oxford-102 Flowers、Flickr30k和MSCOCO。
综上所述,本文工作的主要贡献包括:
1)提出了一种新的表示学习方法LapsCore,以便于明确学习细粒度跨模式关联。它通过求解颜色来工作推理子任务、图像着色、文本完成和图像特征通道完成。
2)在具有挑战性的语言指导的人员搜索数据集CUHK-PEDES上进行了广泛的实验。事实证明,LapsCore可以有效地带来可观的性能提升并实现最先进的结果。
3)所提出的方法被证明是通用的,可以纳入不同的基线并带来改进。在其他跨模态检索任务中也证实了该方法的有效性。
在本节中,将介绍所提出的方法LapsCore。如上图(左部分)所示,LapsCore通过两个颜色推理子任务(文本引导图像着色(IC)和图像引导文本完成(TC))生成代表性的多模态特征。
IC任务旨在利用文本描述对灰度图像进行着色,这些灰度图像从原始图像处理为灰度图像。在此任务中,模型努力理解标题,并探索用于着色的有效信息。因此,可以构建文本到图像的关联。
整个任务可以转化为像素回归问题。多模态回归模型表示为,以灰色图像和描述语句对作为输入,并输出恢复的图像。将原始彩色图像I设置为目标,并使用像素均方误差损失:
为了处理这项任务,作者采用了U-Net框架,该框架对灰色图像进行编码,并通过融合文本信息将其解码为彩色图像,如上图(左上角)所示。在编码阶段,我们从输入中提取多尺度视觉特征。将比例为s的特征图表示为,其中h、w、c分别表示高度、宽度和通道。在文本分支中,描述语句被标记并输入到嵌入层。然后,LSTM提取文本特征。
在解码阶段,视觉特征应与文本特征融合以进行着色。因此,我们设计了多模态SE块,应用通道注意机制,以便文本信息可以影响图像特征通道。多模SE块中的操作如上图所示(右上角的灰色虚线框)。首先,视觉特征图Y通过全局池化被压缩为特征向量。与文本特征向量X concat,然后将馈入两层多层感知器和softmax层以生成注意向量。最后,利用将更新为多模式表示:
其中下标表示通道的索引,是标量。
U-Net的解码器由几个反卷积层组成。首先,编码器中的最后一个穿过第一个反卷积层,以生成特征映射。每个与SE块输出串联,并通过反卷积层生成更大的。作为最后一步,给定最后一个反卷积层中的,使用简单的上采样和卷积来预测目标。
双重任务TC需要利用彩色图像来完成带有彩色单词空缺的文本描述。对于每个句子,删除所有颜色单词以创建 “无色” 描述。这些空位应该通过分析不同图像区域的前景色来填充。这样,可以桥接图像到文本的关系。
此任务可以视为VQA问题。VQA模型,表示为,以彩色图像,和带有空缺的文本句子作为输入,并输出缺少的颜色单词。目标答案是从原始描述中删除的颜色单词。采用典型的交叉损失,公式为:
作者参考了流行的VQA模型 (双线性注意网络 (BAN)) 的结构来解决TC任务。见上图(右下角),视觉和文本特征由MobileNet和LSTM从输入数据中提取。将文本特征表示为和视觉特征为,其中N是序列长度,ρ是LSTM输出维度,φ表示MobileNet输出的通道号,M=h×w是空间维度的乘积。给定两个模态特征X和Y,通过计算特征patch之间的模糊度分数生成若干双线性注意力图,公式如下:
其中和是投影矩阵,是一个全一向量,,其中g表示注意力图索引,,表示Hadamard积。
在注意力图的帮助下,X和Y融合成联合表示。残差学习方法用于提高表征能力。在第g个残差块中,输出的计算公式为:
其中是一个全一向量,投影矩阵为。通过将N设置为K,将X用作初始输入。生成中间表示的函数,定义为,其中,其第k个元素计算为:
其中,矩阵的下标k表示列的索引。
给定最后一个残差块输出的联合特征表示,采用多层感知器(MLP)分类器预测每个单词空缺的颜色类别。
彩色图像由3个通道“YCbCr”组成,灰度图像是删除两个颜色通道“Cb”和“Cr”的结果。重新思考IC任务,其目的是利用文本颜色信息来恢复两个缺失的通道。虽然这种方法可以通过颜色桥接跨模态关联,但当颜色在描述中很小时(例如,在MSCOCO数据集中),可能无法有效地学习文本信息。因此,我们提出了一种广义的IC,表示为,它使用文本来完成图像特征的缺失通道。
如上图所示,ResNet18在识别任务中预训练,以从图像中提取丰富的表示,然后“冻结”为特征生成器。作者屏蔽了图像特征的一些通道,并将屏蔽后的特征输入到完成模型中,以完整的特征为目标。中的完井模型和损失函数与IC中的相同,只是输入和输出比例相应地调整。
该方法可以作为一种多模态表示学习方法纳入流行的图像文本匹配算法。交叉模态投影匹配和分类(CMPM/C)模型采用了通用框架,该框架分别采用LSTM和MobileNet作为文本和视觉特征提取器。在这里选择CMPM/C作为跨模式匹配模块来实现LapsCore,并且它可以很容易地推广到该框架的其他方法。为了合并,作者删除了CMPM/C中的特征提取层,替换为IC和TC模块的表示层,如图2的左部分所示。将CMPM/C中的匹配损失定义为,然后将/总体多任务损失L计算为:
其中是平衡每个子任务重要性的标量因子。将合并到CMPM/C的方式类似,多任务损失写为:
其中是一个平衡因子。
上表展示了本文方法和SOTA结果的对比结果。
上表展示了本文提出的不同模块对实验结果的影响。
给定相同的语言查询,基线(CMPM/C)和本文的方法(CMP+IC&TC)的检索结果如上图所示。相比之下,本文的方法更有效地检索匹配的人(第一行)。它还揭示了LapsCore使模型对颜色更敏感,从而使检索结果更合理。
上图展示了本文方法对不同的图片进行着色的结果。
上图展示了对着色模块改为其他方法的可视化。
上表展示了这些变体的性能。
上表展示了在其他图文检索数据集上进行检索的实验结果。
在本文中,作者提出了LapsCore,它使用两个颜色推理子任务来改进语言引导的人搜索的表示学习。第一种方法旨在利用文本信息对灰度图像进行着色。在双向上,利用彩色图像来完成标题中的彩色文字空缺。此外,作者提出了完整的视觉特征通道,适用于一般的图像文本匹配任务,其中颜色在标题中不占主导地位。定量和定性实验结果以及广泛的消融研究表明了该方法的优越性。
已建立深度学习公众号——FightingCV,关注于最新论文解读、基础知识巩固、科技新闻速递,欢迎大家关注!!!
FightingCV交流群里每日会发送论文解析,进行学术交流,加群请添加小助手wx:FightngCV666,备注:地区-学校(公司)-名称
面向小白的顶会论文核心代码学习:https://github.com/xmu-xiaoma666/External-Attention-pytorch
[1]
https://ieeexplore.ieee.org/document/9711140/: https://ieeexplore.ieee.org/document/9711140/
本文由 mdnice 多平台发布
这是项目《行人检测(人体检测)》系列之《Android实现人体检测(含源码,可实时人体检测)》;本篇主要分享将Python训练后的YOLOv5的人体检测模型移植到Android平台。我们将开发一个简易的、可实时运行的人体检测Android Demo。
考虑到原始YOLOv5的模型计算量比较大,鄙人在YOLOv5s基础上,开发了一个非常轻量级的的人体检测模型yolov5s05_320。从效果来看,Android人体检测模型的检测效果还是可以的,高精度版本YOLOv5s平均精度平均值mAP_0.5:0.95=0.84354,而轻量化版本yolov5s05_416平均精度平均值mAP_0.5:0.95=0.76103左右。APP在普通Android手机上可以达到实时的检测识别效果,CPU(4线程)约30ms左右,GPU约25ms左右 ,基本满足业务的性能需求。
先展示一下Android Demo人体检测的效果
【Android APP体验】https://download.csdn.net/download/guyuealian/87441942
【项目源码下载】 行人检测(人体检测)3:Android实现人体检测(含源码,可实时人体检测)
【尊重原创,转载请注明出处】https://blog.csdn.net/guyuealian/article/details/128954615
更多项目《行人检测(人体检测)》系列文章请参考:行人检测(人体检测)1:人体检测数据集(含下载链接):https://blog.csdn.net/guyuealian/article/details/128821763行人检测(人体检测)2:YOLOv5实现人体检测(含人体检测数据集和训练代码):https://blog.csdn.net/guyuealian/article/details/128954588行人检测(人体检测)3:Android实现人体检测(含源码,可实时人体检测):https://blog.csdn.net/guyuealian/article/details/128954615行人检测(人体检测)4:C++实现人体检测(含源码,可实时人体检测):https://blog.csdn.net/guyuealian/article/details/128954638
如果需要进行人像分割,实现一键抠图效果,请参考文章:《一键抠图Portrait Matting人像抠图 (C++和Android源码)》
目前收集VOC,COCO和MPII数据集,总数据量约10W左右,可用于人体(行人)检测模型算法开发。这三个数据集都标注了人体检测框,但没有人脸框,考虑到很多项目业务需求,需要同时检测人脸和人体框;故已经将这三个数据都标注了person和face两个标签,以便深度学习目标检测模型训练。
关于人体检测数据集使用说明和下载,详见另一篇博客说明:《行人检测(人体检测)1:人体检测数据集(含下载链接)》 行人检测(人体检测)1:人体检测数据集(含下载链接)_AI吃大瓜的博客-CSDN博客
官方YOLOv5给出了YOLOv5l,YOLOv5m,YOLOv5s等模型。考虑到手机端CPU/GPU性能比较弱鸡,直接部署yolov5s运行速度十分慢。所以本人在yolov5s基础上进行模型轻量化处理,即将yolov5s的模型的channels通道数全部都减少一半,并且模型输入由原来的640×640降低到416×416或者320×320,该轻量化的模型我称之为yolov5s05。轻量化后的模型yolov5s05比yolov5s计算量减少了16倍,参数量减少了7倍。
下面是yolov5s05和yolov5s的参数量和计算量对比:模型input-sizeparams(M)GFLOPsyolov5s640×6407.216.5yolov5s05416×4161.71.8yolov5s05320×3201.71.1
yolov5s05和yolov5s训练过程完全一直,仅仅是配置文件不一样而已;碍于篇幅,本篇博客不在赘述,详细训练过程请参考: 《行人检测(人体检测)2:YOLOv5实现人体检测(含人体检测数据集和训练代码)》https://blog.csdn.net/guyuealian/article/details/128954588
训练好yolov5s05或者yolov5s模型后,你需要将模型转换为ONNX模型,并使用onnx-simplifier简化网络结构
GitHub: https://github.com/daquexian/onnx-simplifierInstall: pip3 install onnx-simplifier
目前CNN模型有多种部署方式,可以采用TNN,MNN,NCNN,以及TensorRT等部署工具,鄙人采用TNN进行Android端上部署:
TNN转换工具:(1)将ONNX模型转换为TNN模型,请参考TNN官方说明:TNN/onnx2tnn.md at master · Tencent/TNN · GitHub(2)一键转换,懒人必备:一键转换 Caffe, ONNX, TensorFlow 到 NCNN, MNN, Tengine (可能存在版本问题,这个工具转换的TNN模型可能不兼容,建议还是自己build源码进行转换,2022年9约25日测试可用)
项目实现了Android版本的人体检测Demo,部署框架采用TNN,支持多线程CPU和GPU加速推理,在普通手机上可以实时处理。Android源码核心算法YOLOv5部分均采用C++实现,上层通过JNI接口调用
如果你想在这个Android Demo部署你自己训练的YOLOv5模型,你可将训练好的Pytorch模型转换ONNX ,再转换成TNN模型,然后把TNN模型代替你模型即可。TNN推理时出现:Permute param got wrong size 官方YOLOv5: GitHub - ultralytics/yolov5: YOLOv5 in PyTorch > ONNX > CoreML > TFLite
如果你是直接使用官方YOLOv5代码转换TNN模型,部署TNN时会出现这个错误Permute param got wrong size,这是因为TNN最多支持4个维度计算,而YOLOv5在输出时采用了5个维度。你需要修改model/yolo.py文件
export.py文件设置model.model[-1].export = True:
TNN推理时效果很差,检测框一团麻
这个问题,大部分是模型参数设置错误,需要根据自己的模型,修改C++推理代码YOLOv5Param模型参数。
input_width和input_height是模型的输入大小;vector<YOLOAnchor> anchors需要对应上,注意Python版本的yolov5s的原始anchor是
而yolov5s05由于input size由原来640变成320,anchor也需要做对应调整:
因此C++版本的yolov5s和yolov5s05的模型参数YOLOv5Param如下设置
运行APP闪退:dlopen failed: library "libomp.so" not found
参考解决方法:解决dlopen failed: library “libomp.so“ not found_PKing666666的博客-CSDN博客_dlopen failed
【Android APP体验】https://download.csdn.net/download/guyuealian/87441942
APP在普通Android手机上可以达到实时的人体检测效果,CPU(4线程)约30ms左右,GPU约25ms左右 ,基本满足业务的性能需求。
【Android APP体验】https://download.csdn.net/download/guyuealian/87441942
【项目源码下载】 行人检测(人体检测)3:Android实现人体检测(含源码,可实时人体检测)
整套Android项目源码内容包含:提供快速版yolov5s05人体检测模型,在普通手机可实时检测识别,CPU(4线程)约30ms左右,GPU约25ms左右提供高精度版本yolov5s人体检测模型,CPU(4线程)约250ms左右,GPU约100ms左右Demo支持图片,视频,摄像头测试
更多项目《行人检测(人体检测)》系列文章请参考:行人检测(人体检测)1:人体检测数据集(含下载链接):https://blog.csdn.net/guyuealian/article/details/128821763行人检测(人体检测)2:YOLOv5实现人体检测(含人体检测数据集和训练代码):https://blog.csdn.net/guyuealian/article/details/128954588行人检测(人体检测)3:Android实现人体检测(含源码,可实时人体检测):https://blog.csdn.net/guyuealian/article/details/128954615行人检测(人体检测)4:C++实现人体检测(含源码,可实时人体检测):https://blog.csdn.net/guyuealian/article/details/128954638
必须可以水,注意力机制最容易创新。
尝试加入不同的注意力机制。
软注意力机制与硬注意力机制
全局和局部注意力机制
分层注意力机制
层次注意力机制
自顶向下注意力机制
多步注意力机制
多头注意力机制
多维自注意力机制
方向型自注意力机制
双向分块自注意力机制
强化学习自注意力机制
结构化自注意力机制
都可以进行一些微小改进
行人重识别近几年获得了在测试结果上的大幅提升,甚至超过了人的分辨能力,但是我们在实际应用上仍有很多待解决的问题。在本文中,我们take a step back, 提出了一些问题和潜在的解决方案,主要以我们reler组的尝试为主,包括大家比较熟知的 PCB / HHL/ PUL/ SPGAN/ DG-Net等工作,抛砖引玉。 希望能为未来这个领域的发展提供一些新的视野。
由于篇幅,我们只能展示有限的工作,我们respect所有在这个领域作出贡献的老师同学们。感谢大家!这篇文章中提到多数文章的代码,我们都开源在github了,如果没有找到,可以联系 @郑哲东 或者联系对应作者来提供。感谢大家的支持和关注!
---------------更新-------------
B站讲解视频: 【极市】郑哲东:从行人重识别到无人机定位_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
背景介绍
行人重识别任务就是一个跨摄像头检索的任务。这个任务的出现是由于 日益提升的公共安全需求 和 在公共区域的大型摄像头网络 (如迪士尼乐园/商场/大学校园)。
首要的难度是在于不同摄像头下,由于视角的差异所引入的appearance变化。同时,也需要一些细粒度的信息来区分不同人。
Reference: Zheng L, Bie Z, Sun Y, et al. Mars: A video benchmark for large-scale person re-identification[C]//European Conference on Computer Vision. Springer, Cham, 2016: 868-884.
近几年,supervised person re-id 一直在提升结果。
今年我们组也在CVPR 2020 Workshop的比赛中,在车辆重识别赛道拿到了第一名。我们发现仍有一些问题没有被解决,包括训练数据等等方面。
目前已经有了很多数据集,但是相比ImageNet 一百万的训练数据,目前reID的数据集都还是相对小。
代码:layumi/AICIty-reID-2020
Reference : Zheng, Z., Jiang, M., Wang, Z., Wang, J., Bai, Z., Zhang, X., Yu, X., Tan, X., Yang, Y., Wen, S. and Ding, E., 2020. Going beyond real data: A robust visual representation for vehicle re-identification. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops(pp. 598-599).
Reference: NEU-Gou/awesome-reid-dataset  所以,总的来说,在实际场景中,应用reID的挑战仍是多个方面的,包含 数据/效率/性能等等方面。对应也有一些潜在的解决方案,我们组做了一些尝试。
所以,总的来说,在实际场景中,应用reID的挑战仍是多个方面的,包含 数据/效率/性能等等方面。对应也有一些潜在的解决方案,我们组做了一些尝试。 对于有限的数据,最直接的方案就是补充数据。但是额外的数据往往需要额外的标注。同时,我们无法保证额外数据的分布是否改变(比如额外数据是一天内不同时间采集的,光照不同)。
对于有限的数据,最直接的方案就是补充数据。但是额外的数据往往需要额外的标注。同时,我们无法保证额外数据的分布是否改变(比如额外数据是一天内不同时间采集的,光照不同)。

Reference: Zheng, Z., Yang, X., Yu, Z., Zheng, L., Yang, Y., & Kautz, J. (2019). Joint discriminative and generative learning for person re-identification. InProceedings of the IEEE conference on computer vision and pattern recognition(pp. 2138-2147).
Code: NVlabs/DG-Net
2. 除了训练数据,大家最关心的就是训练的有效性了。如何挖掘数据背后的故事,特别是局部细节。


3. 在行人重识别的精准度有了长足发展之后,效率也是一个必须考虑的方面。

4. 如果标注很有限,该怎么学习呢?



5. 训练集与测试集的采集方式不同,就导致了domain gap。这也是在实际落地reID遇到的最大问题。




6.最后,在非限制场景中,往往会遇到遮挡等等环境问题。如何学习一个鲁棒的行人表示?



Reference: Zheng, Z. and Yang, Y., 2020. Person Re-identification in the 3D Space.arXiv preprint arXiv:2006.04569.
Code: layumi/person-reid-3d
目前reID任务已经有了长足的发展,未来可能的方向,包含 鲁棒性,快速学习,在线学习等等。基本还是以落地实用 为导向。

感谢大家,我们提出了一些问题和潜在的解决方案,主要以我们reler组的尝试为主,抛砖引玉。 希望我们微小的工作能为未来这个领域的发展提供一些新的视野。
由于篇幅,我们只能展示有限的工作,我们respect所有在这个领域作出贡献的老师同学们。感谢大家!
最后感谢看完,欢迎关注我们实验室的知乎专栏 和我的其他文章,每周会不定时更新~
记得一键三连,祝大家paper全都accept!悉尼科技大学ReLER实验室郑哲东:TMM|车辆重识别的一些实践郑哲东:【新无人机数据集】从 行人重识别 到 无人机目标定位郑哲东:简单行人重识别代码到88%准确率
1. 背景
1.1 概念
人类属性识别(Human Attribute Recognition,HAR)或行人属性识别(Pedestrian Attributes Recognition,PAR),从预定义的属性列表中预测一组属性来描述该行人的特征。下面是文中的一张图,比如,蓝色框中识别出来这个人的属性有:短发、戴眼镜、学士服、黑裤子、黑鞋、蓝色自行车、男性等。
行人属性识别挖掘到的是行人的高层语义信息,这些信息和低层特征不同,对视角变换和成像条件的变化比较鲁棒。
1.2 任务分析
1.2.1 multi-task learning
多任务学习(multi-task learning)指的是将每一类属性识别作为一个任务,前面共享神经网络参数,最后N个全连接层并列,各负责一个属性任务的分类,如下图所示:
1.2.2 multi-label learning
多标签学习(multi-label learning) 是将所有分类作为一个任务处理,用一个全连接层对属性分类,只是预测的不是单一类别,而是类别列表,如下图所示:
1.3 难点及挑战
在进行行人属性识别中,存在以下挑战:属性各异:行人属性各不相同,有的需要浅层特征,有的需要深层特征,有的需要局部特征,有的需要全局特征;数据不均衡:不是说训练集中的每一个人都具备属性列表中的所有属性,每个人具备的只是属性列表中的部分属性,因此造成了属性的数据不均衡;多视角:不同视角下看同一个人可能会有不同的感受;遮挡:行人的某些部位被遮挡会影响属性识别;低分辨率:监控场景下、远距离抓拍的行人图像,分辨率往往很小;光线变化:不同强度、不同角度的光线影响成像效果;模糊:行人运动时的运动模糊影响属性识别。
2. Benchmarks
2.1 数据集
2.1.1 RAP数据
RAP数据共41585图像,分辨率从36 * 92 到 344 * 554,72个属性(69个二分类属性,3个多分类属性),RAP数据集还针对行人拍摄位置进行了不同viewpoint的分类和不同行人遮挡部位的分类,并在其论文中详细介绍了不同拍摄视角和不同遮挡部位对行人属性识别带来的影响。
其样本的viewpoint和occlusion分布如下所示:
其属性标签如下所示:
2.1.2 RAP-2.0
采集自720P的室内监控场景,2589个人的84928幅图像,分辨率从33*81到415 * 583,属性标签和RAP一致。
2.1.3 PETA数据
PETA数据来自于10个小的行人重识别数据集,19000张图像,分辨率从17 * 39 到 169 * 365,来自于8705个人,61个二分类属性和4个多分类属性。该数据集的缺点是对同一个人的不同图像标注完全相同的属性,即便在某些区域不可见的情况下,依然保持属性不变(如在鞋子被遮挡的情况下,仍然对该图像标注了鞋子的信息)。
2.1.4 PA-100K数据
PA-100K是2017年底发布的最新的、最大的,针对行人属性识别的数据集,包括10万个行人样本,每个样本分26个属性。分辨率范围:50 * 100 to 758 * 454。
2.1.5 PARSE27K数据
PARSE27K数据来自于8段城市场景下移动摄像机拍摄的视频,27000张图像,每幅图像标注10个属性,8个是二分类属性,某个属性缺失时标注为N/A。
2.1.6 Market1501-attribute数据
Market1501-attribute是清华门口一个市场的六个相机拍摄的视频,1501个人的32668个标注框。每一个标注的人至少在两个相机中出现过。每个图像标注了27个属性。
2.1.7 CRP数据
来自于7个视频的27454幅图像,含四类属性,分别是年龄、性别、体型和衣服类型。
2.1.8 其他数据情况
其他一些数据集的参数及链接如下表:DatasetNumsAttributeSourcePETA Dataset1900061 binary and 4 multi-classoutdoor & indoorRAP Dataset4158569 binary and 3 multi-classindoorRAP 2.0 Dataset8492869 binary and 3 multi-classindoorPA-100K Dataset10000026 binary attributesoutdoorWIDER Attribute Dataset1378914 binary attributesWIDER imagesMarket-1501_Attribute3266826 binary and 1 multi-classoutdoorDukeMTMC-Attribute3418323 binary attributesoutdoorParse27k Dataset270008 binary and 2 multi-classoutdoorDatabase of Human Attributes934427 binary attributesimage site FlickrCRP Dataset274541 binary and 13 multi-classoutdoorClothing Attributes Dataset185623 binary and 3 multi-classSartorialist and FlickrBerkeley-Attributes of People dataset80359 binary attributesH3D dataset PASCAL VOC 2010
2.2 评价指标
2.2.1 mean accuracy(mA)
mA分别计算每个属性正样本和负样本分对的比例,再二者平均作为这一个属性的准确度,接着再对所有属性取平均作为最后的mA指标。具体计算如下所示:
其中L是属性的数量,TPi和TNi是正确分类的正类和负类的数量,Pi和Ni是正类和负类的总数量。
2.2.2 example-based evaluation criterions
这组评价指标针对每个样本进行评价,通过计算每个样本分对属性和分错属性的关系计算一组指标。具体计算如下所示:
其中,N是样本数量,Yi是第i个样本标注为正类的标签,f(xi)表示第i个样本预测为正类的标签。
2.2.3 ROC曲线
ROC曲线:计算每个属性类别的分类召回率和FPR,召回率是指正确检测到的正例占所有正例的比例,FPR是被误认为是正例的负例数量占所有负例的比例。根据recall和FPR可以绘制ROC曲线,并可以进一步计算AUC。
3. 模型概述
3.1 主流方法
最早的行人属性识别通过人工提取特征,并针对每个不同的属性分别训练分类器。随着CNN的发展,人们开始尝试把所有属性置于同一个网络进行多任务训练,共享网络参数,并发现多任务训练能够带来更好的效果。
目前行人属性识别的基本方法是将整个图片扔进同一个CNN网络,并输出多个代表属性的标签进行分类。基于这个最基本的方法,目前最新的工作主要集中在如何对不同粒度、不同规模的属性进行识别,如何通过提取场景中的上下文信息辅助属性的识别,以及如何提取不同属性间的相关性信息。不同粒度属性的提取通过建立不同网络层次的分支分别进行提取,再将不同分支提取的特征进行拼接作为最终特征。
上下文信息的提取通过建立LSTM网络结构,使得上下文能够传入到后续提取特征的过程当中。不同属性间相关性信息通过多属性联合训练或利用LSTM网络保存上一个属性的识别信息进行提取。
3.2 相关工作
3.2.1 FT-CNN
论文:Re-id Using CNN Features Learned from Combination of Attributes大佬们都在玩{精选官网网址: www.vip333.Co }值得信任的品牌平台!
期刊会议:ICPR-2016
关键词:全局特征、属性组合、联合损失、预训练微调
参考链接:https://blog.csdn.net/weixin_37753215/article/details/81748533
主要贡献:(1) 基于AlexNet预训练参数进行行人属性数据集的微调;(2) 各属性分别分类+属性暴力组合分类;(3) 各属性分类损失与组合分类损失联合。
内容概要:
(1)5个卷积层和3个全连接层
(2)属性的组合
(3)联合损失函数
3.2.2 Based Deep Hierarchical Contexts
论文:Human Attribute Recognition by Deep Hierarchical Contexts
期刊会议:ECCV-2016
关键词:局部特征、上下文信息、特征融合
参考链接:https://blog.csdn.net/cv_family_z/article/details/78223287
主要贡献:(1) 利用目标区域附近的上下文信息辅助识别;(2) 多种特征融合分类;
内容概要:
(1)利用上下文信息辅助识别
(2)给定输入图片,计算其Gaussian金字塔,并送入CNN网络中,以得到多尺度的特征图。从特征图中提取四种边界框区域的特征集合:整个目标人物、目标人物的选定部位、图像金字塔中的邻近部位、全局图像场景,后两种特征集分别对应分层内容信息:以人为中心信息和场景信息。分别对四种区域进行分数计算,并相加以得到最终的属性分数。
(3)属性得分来自四部分
这里的a表示属性,b表示检测出的人物框,S表示检测出的各身体部位集合,N(sa*)表示考虑多少个上下文相似部位(包括其自身,这样保证算法在只有一个人的图中也适用),I表示当前图片。
(4)对于第二个分支,并不是所有的身体部位都对识别属性有很大帮助,比如识别头发长度和下半身部位就没啥联系,所以对于每一个属性的识别只select the most informative part 参与最后属性得分的计算。
(5)对于第三个分支,以Gaussian pyramid as input image输入CNN,N(sa*)取多少是在实验中调参得到的。选择上下文相似部位时包括其自己,这样保证在只有一个人的图中也适用。
(6)对于第四个分支,通过Wsc(应该就是图中的skiing0.8)对进行筛选,使得只有场景相关性很强的信息得以保存下来,其他信息被忽略。
3.2.3 HydraPlus-Net
论文:HydraPlus-Net: Attentive Deep Features for Pedestrian Analysis
期刊会议:ICCV-2017
关键词:注意力机制、局部、全局、特征融合
参考链接:https://www.pianshen.com/article/3448824745/
代码:https://github.com/xh-liu/HydraPlus-Net
主要贡献:
(1)模型能够从浅层到语义层捕获注意力;
(2)挖掘多尺度的可选注意力特征,充实最终的行人特征表示;
(3)提取出细节和局部特征来充实高层全局特征,这些特征在细粒度的行人分析任务中是非常重要的;
(4)提出多方向注意机制模块(multi-directional attention,MDA),提取多层(multiple level)特征,包含局部和全局特征,进行多层特征融合,进行细粒度的行人分析;
内容概要:
(1)Main Net(M-Net):单纯的CNN结构,论文的实现是基于inception_v2,包含三个inception block,还包含几个低层卷积层;
(2)Attentive Feature Net(AF-Net):三个分支,每个分支有三个inception_v2 block(与M-Net一样)和一个MDA;
(3)三个MDA分别称为F(αi),αi是由inception block i的输出特征Fi生成的attention maps,生成方式是通过一个1×1的conv+BN+ReLU得到,记为:
这里的L表示attention map的channels,文章中L=8,然后αi作用于inception block k是通过element-wise multiplication(对应元素相乘),表示如下:
最后concat这L个attention feature maps作为最终的特征表示。
(4)AF-Net和M-Net的输出concat后通过global average pooling (GAP)和全连接(FC)层进行融合得到logits。
(5)分阶段训练流程:①训练M-Net,提取基本特征;②将M-Net复制三次,得到AF-Net的三个分支,每个MDA模块有三个子分支组成,即临近的三个不同的inception blocks,依次微调每个blocks,即共有9个blocks需要微调;③微调完成后,固定AF-Net和M-Net,训练全局平均池化层(GAP)和全连接层(FC);④输出层:属性识别使用交叉熵损失函数,行人ReID使用softmax函数。
模型结果:
3.2.4 JRL model
论文:Attribute Recognition by Joint Recurrent Learning of Context and Correlation
期刊会议:ICCV-2017
关键词:LSTM、注意力、相关性、上下文、端到端
参考链接:https://blog.csdn.net/chanbo8205/article/details/109654044
https://blog.csdn.net/pancongpcc/article/details/96269608
主要贡献:(1)提出了一个联合循环学习(JRL)方法,行人属性相关性和上下文信息在一个统一的模型;(2)构建了一种能够共同学习图像级上下文信息和属性级序列关联的端到端编解码器体系结构;
内容概要:
(1)Inter-Person Similarity Context 结构针对一张输入的image I,搜寻相似度最高的k个训练image(训练过程),然后用和上面相同的方法输出每个image的综合特征z,并将所有选取的图片和输入的图片置于一起,每个特征元素取最大值,作为行人间的上下文特征。每个框首先经过基础CNN(Alexnet),将整体的feature map垂直分成m个区域分别进行池化,将m个区域的池化输出拼接在一起输入全连接层,输出向量用L2 distance搜索训练数据集中相似度最高的k个image。
(2)Intra-Person Attribute Context 结构针对一张行人框,把这个行人框垂直分为6个部分,再用6个LSTM单元对每个部分提取特征,最后一个单元输出的状态就可以看作是这种图片综合的一个特征表示。这样的提取方式可以提取身体不同部分的空间依赖性以及局部拓扑关系的上下文信息。
(3)Inter-Attribute Correlation 结构输入行人间上下文特征z* 和每一个图片的上下文信息z。此外,根据一种图片不同部分对不同属性识别的贡献不同,加入注意力机制,为每个属性分配一个w参数,选取如何提取6个部分的比例。(实际上个人感觉就是一个输出为属性个数的向量的全连接层)。z*作为第一个lstm的初始状态,z相当于每个LSTM的输入x。有多少属性就有多少个LSTM,每个LSTM输出y对应一个属性的标签,且这个y被输入到后续的LSTM当中,作用于属性间相关性的提取。
(4)最后属性排列的顺序有很多种排法,如出现频率优先,随机排序等等。给一张test image,根据设定的10种排法产生10个结果,然后投票少数服从多数生成最终结果。
模型结果:
3.2.5 VSGR
论文:Visual-semantic Graph Reasoning for Pedestrian Attribute Recognition
期刊会议:AAAI-2019
关键词:GCN、端到端
参考链接:https://blog.csdn.net/lowellyu/article/details/104865921
主要贡献:(1)将行人属性识别作为属性序列预测的问题,并且提出了一种新的视觉语义图推理框架来解决这一问题;(2)通过图卷积网络(GCN)进行推理,这两种类型的图可以分别描述图像局部区域的空间关系和属性的潜在语义关系;(3)提出了端到端的学习框架,在这两个图之间实现了信息的互嵌入以指导彼此的关系学习。
内容概要:
(1)算法主要包含两个子网络,即视觉-语义子网络和语义-视觉子网络。
(2)在视觉语义子网络中,首先将人体图像分割为固定数量的局部部分,然后构造一个图,图的节点是各局部,边是不同部分的相似性。与常规的关系建模不同的是,它们既采用零件之间的相似关系,又采用拓扑结构将零件与其相邻区域连接起来。具体过程就是利用空间图学习图像特征表示,获取整个行人图像中不同身体部位之间的空间关系。然后将学习到的空间上下文嵌入到语义空间中,指导有向语义图上的属性之间的关系学习。
(3)在语义视觉子网络中,首先采用有向语义图来捕捉属性之间的语义关系。在每个预测步骤中,将当前属性节点的输出嵌入到空间图中,进行语义感知特征学习,预测下一个属性。
模型结果:
3.2.6 CoCNN
论文:Attribute Aware Pooling for Pedestrian Attribute Recognition
期刊会议:IJCAI-2019
关键词:multi-branch、共现矩阵、矩阵融合
参考链接:https://blog.csdn.net/chanbo8205/article/details/109637327
https://blog.csdn.net/lowellyu/article/details/104880781
主要贡献:(1)提出了一种新的行人多属性识别CNN架构,通过探索不同属性之间的相关性,即属性共现先验。
内容概要:
(1)首先输入图片送入Backbone提取浅层高分辨率特征F,分为多个分支计算属性预测值P,具体根据身体部位分为四个分支,第一个分支为F整体,然后将F划分为4、6、6三个部分,分别表示人的头部、上半身、下半身,分别计算属性预测值P;
(2)然后利用属性感知池化Attribute Aware Pooling将多分支预测值P与属性条件矩阵融合得到辅助概率P+,得到如下实际输出:
(3)辅助概率P+通过条件概率矩阵C(上下文信息)和输出概率矩阵Q(共现表)得到:
(4)对于含有n个样本、k个标签的训练集,设Ni为第i个标签出现的次数,则①表示第i个标签的概率,设第i个标签和第j个标签的相关性为Nij,则ai和aj的联合概率为②,同样得到ai和aj的条件概率为③:



(5)预测某一分支需要融合多分支的信息,给定m个分支{b1,b2,...,bm},对于一个分支bl,属性aj与除bl之外的分支之间的相关性可表示为:
该相关性比较难计算,实际应用中用如下方式计算:
模型结果:
3.2.7 HFE框架
论文:Hierarchical Feature Embedding for Attribute Recognition
期刊会议:CVPR-2020
关键词:联合损失、HFE loss、绝对边界正则化
参考链接:https://blog.csdn.net/chanbo8205/article/details/111319694
主要贡献:(1)我们提出了基于属性语义集成ID信息的HFE框架,以实现细粒度特征嵌入。针对类间和类内约束,提出了一种新的HFE loss;(2)我们构造了一个绝对边界正则化,通过在一个绝对约束下强化原来的triplet loss;(3)我们引入了动态损失权值,迫使特征空间从原点过渡到改进的HFE 受限空间。
内容概要:
(1)首先对属性分类应用Cross Entropy loss(CE loss),
(2)此外,新增HFE loss进行权值w的辅助度量学习,
(3)HFE loss包括inter-triplet loss, intra-triplet loss和绝对边界正则化(ABR),
(4)triplet loss:triplet loss已广泛应用于度量学习。对一系列{xai, xpi, xni}三元组进行训练,其中xai和xpi是来自同一标签的图像特征,xni是来自不同标签的图像特征。a、p、n分别是anchor、positive、negative sample的缩写,
这里d(.)代表欧氏距离,α是使d(xai, xni)和d(xai, xpi)的距离大于α的边界。[z]+表示最大(z, 0),当间隙大于α时,triplet loss为0。
三元组构建过程,从训练数据集中随机选一个样本,该样本称为Anchor,然后再随机选取一个和Anchor (记为xa)属于同一类的样本和不同类的样本,这两个样本对应的称为Positive (记为xp)和Negative (记为xn),由此构成一个(Anchor,Positive,Negative)三元组。
(5)Inter-class 类间Triplet Loss:三联体,将triplet loss扩展到属性分类场景中。xaij为样本Ii的第j个属性的特征,与xaij的正、负样本的特征相关联,即xp3ij, xn1ij。这里我们在属性级别上定义三元组,α1是类间边界。
(6)Intra-class 类内Triplet Loss:五联体,
(7)triplet losss仅限制d(xa ij, xp ij)与d(xa ij, xn ij)的差值,而忽略绝对值。该差异依赖于批量选择的三元组,在整个训练数据集中很难保证d(xa ij, xp ij) < d(xa ij, xn ij)。在我们的约束条件中,为了保证属性具有判别性的类内特征嵌入,我们从xa ij中提取相对于xp ij1的xp ij2。虽然margin α2 < α1,Lintra可以间接与类间边界相互作用。考虑这两个因素,我们强迫d(xa ij, xn ij)大于绝对距离α3,称为绝对边界正则化(ABR)。
(8)在训练初期,特征空间不够好,无法进行五元组选择。因此,一开始对HFE loss施加较大的权值可能会放大了初始模型产生的噪声。为了解决这个问题,我们在一开始设置HFE loss的小权值,使原始的CE loss在训练优化中发挥主要作用,产生基本的特征空间。然后我们扩大权重,细化原始特征空间,使其更具有细粒度。因此,我们引入动态损失权值,对由[51]提出的复合函数进行非线性地控制从小到大的损失权值。式8中,T为训练总迭代次数,iter为当前迭代次数。w0是一个给定值。
模型结果:
3.2.8 模型对比
3.3 未来发展方向
关于行人属性识别的未来发展趋势,因为考虑到目前这个领域基于CNN的方法也只是刚刚起步,各方面资料和数据都不算完备,还有许多需要改进的地方。这里我只针对我认为的几个比较重要的发展方向进行猜想:
(1)在识别过程中考虑不同viewpoint和不同遮挡对属性识别的影响,这需要在训练过程中就加入以上两个方面的元素,并设计新的训练逻辑来利用带有不同viewpoint标注的数据。
(2)设计更好的网络结构全方位的提取不同粒度不同规模的属性特征。我们知道不同的属性需要提取不同层次的特征,目前的方法主要通过设置多个分支来解决这个问题,但是我感觉针对分支的设置以及注意力机制的结合,这个方法还可以再继续优化。
(3)怎么结合检测进行行人属性识别。目前属性识别的研究几乎都是针对检测好的行人框,但是真实场景中需要检测和属性识别一体化的系统。
(4)针对不同的场景,挑选合适的属性。不同的场景对属性的需求也不同。考虑到不同的属性由于其不同粒度和规模的特征,会对模型产生很大的影响,所以我认为针对实际场景我们应该挑选需要的属性,分析属性信息属于的特征层次并由属性驱动我们设计针对性的网络结构。
4. 应用思考
针对我们现有场景,用于监控场景下的需求比较明显,主要识别着装是否异常,可以针对性的进行以下方面的思考和应用:
(1)结合目标检测对监控中人员的安全帽、工作服、安全带等属性进行识别;
(2)通过监控信息的上下帧相似信息来增强模糊属性的信息;
(3)近期的研究都是基于LSTM+attention来抓取上下文信息,而现有的transformer可以一并替代该模块;
(4)其他行人的同部位的属性信息似乎不适用于我们这里的异常着装场景;
(5)标签共现信息也不适用于我们目前的应用场景;
(6)端到端的网络及损失函数的灵活设计是必要的,需要仔细斟酌;
5. 总结
(1)上下文行人信息要根据具体场景确定是否可取,如监控场景、异常场景是不可取的;
(2)多维度的特征融合比较推荐;
(3)注意力特征图可提取不同的语义,抽象出同一行人的不同的视觉模式;
(4)端到端网络减少误差逐级传播;
(5)按区域划分,用LSTM来抓取上下文信息;
(6)训练集内部的相关性来提供额外的相似信息;
(7)通过图卷积网络(GCN)来表征图像局部区域的空间关系和属性的潜在语义关系;
(8)引入标签共现信息,抓取标签内部联系;
(9)设计定制化的损失函数、联合损失;
6. 参考文献
Year-2020Deep Template Matching for Pedestrian Attribute Recognition with the Auxiliary Supervision of Attribute-wise Keypoints, Jiajun Zhang, Pengyuan Ren, Jianmin Li, [arXiv]Gu, Z., Zhang, J., Pan, Z., Zhao, H., & Zhang, L. (2019, July). Clothes keypoints localization and attribute recognition via prior knowledge. In 2019 IEEE International Conference on Multimedia and Expo (ICME) (pp. 550-555). IEEE.[Paper]Ji, Z., Hu, Z., He, E., Han, J., & Pang, Y. (2020). Pedestrian Attribute Recognition Based on Multiple Time Steps Attention. Pattern Recognition Letters. [PRL]Texture and Shape Biased Two-Stream Networks for Clothing Classification and Attribute Recognition, Yuwei Zhang, Peng Zhang, Chun Yuan, Zhi Wang [CVPR2020]Hierarchical Feature Embedding for Attribute Recognition, Jie Yang, Jiarou Fan, Yiru Wang, Yige Wang, Weihao Gan, Lin Liu, Wei Wu [CVPR2020]Rethinking of Pedestrian Attribute Recognition: Realistic Datasets and A Strong Baseline, Jian Jia, Houjing Huang, Wenjie Yang, Xiaotang Chen, and Kaiqi Huang [arXiv] [Code]Multi-Task Learning via Co-Attentive Sharing for Pedestrian Attribute Recognition, Haitian Zeng, Haizhou Ai, Zijie Zhuang, Long Chen, [ICME 2020]Distraction-Aware Feature Learning for Human Attribute Recognition via Coarse-to-Fine Attention Mechanism, Mingda Wu (Beihang University)*; Di Huang (Beihang University, China); Yuanfang Guo (Beihang University); Yunhong Wang (State Key Laboratory of Virtual Reality Technology and System, Beihang University, Beijing 100191, China), AAAI-2020 [Paper]Relation-Aware Pedestrian Attribute Recognition with Graph Convolutional Networks, Zichang Tan (NLPR); Yang Yang (Institute of Automation, Chinese Academy of Sciences); Jun Wan (NLPR, CASIA)*; Guodong Guo (West Virginia University); Stan Li (National Lab. of Pattern Recognition, China), AAAI-2020, [Paper]An Attention-Based Deep Learning Model for Multiple Pedestrian Attributes Recognition, Ehsan Yaghoubi, Diana Borza, Jo˜ao Neves, Aruna Kumar, Hugo Proen¸ca, [arXiv-Paper] [Code]
Year-2019Zhang, S., Song, Z., Cao, X., Zhang, H., & Zhou, J. (2019). Task-aware attention model for clothing attribute prediction. IEEE Transactions on Circuits and Systems for Video Technology (T-CSVT), 30(4), 1051-1064. [Paper]GSR-MAR: Global Super-Resolution for Person Multi-Attribute Recognition. Siadari, Thomhert Suprapto, Mikyong Han, and Hyunjin Yoon. 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW). IEEE, 2019.[Paper]Distraction-Aware Feature Learning for Human Attribute Recognition via Coarse-to-Fine Attention Mechanism, Mingda Wu, Di Huang, Yuanfang Guo Yunhong Wang [Paper] , AAAI-2020 oral presentation.Improving Pedestrian Attribute Recognition With Weakly-Supervised Multi-Scale Attribute-Specific Localization Chufeng Tang, Lu Sheng, Zhaoxiang Zhang, Xiaolin Hu, ICCV-2019, [Paper] [Code]Ji, Zhong, Erlu He, Haoran Wang, and Aiping Yang. "Image-attribute reciprocally guided attention network for pedestrian attribute recognition" Pattern Recognition Letters 120 (2019): 89-95.Zichang Tan, Yang Yang, Jun Wan, Yingyi Chen, Guodong Guo, Stan Z. Li. Attention based Pedestrian Attribute Analysis. IEEE TIP, 2019.Qiaozhe Li, Xin Zhao, Ran He, Kaiqi Huang, Pedestrian Attribute Recognition by Joint Visual-semantic Reasoning and Knowledge Distillation, IJCAI-2019.Kai Han, Yunhe Wang, Han Shu, Chuanjian Liu, Chunjing Xu, Chang Xu, Attribute Aware Pooling for Pedestrian Attribute Recognition, IJCAI-2019Liuyu Xiang, Xiaoming Jin, Guiguang Ding, Jungong Han, Leida Li Incremental Few-Shot Learning for Pedestrian Attribute Recognition, IJCAI-2019.Esube Bekele and Wallace Lawson The Deeper, the Better: Analysis of Person Attributes Recognition, submitted to FG2019Zhiyuan Chen, Annan Li, and Yunhong Wang, Video-Based Pedestrian Attribute Recognition, arXiv paper, 2019 [Paper]Wang, Yiru, Weihao Gan, Wei Wu, and Junjie Yan. Dynamic Curriculum Learning for Imbalanced Data Classification, ICCV 2019.Xin Zhao; Liufang Sang; guiguang ding; Jungong Han; Na Di; Chenggang Yan, Recurrent Attention Model for Pedestrian Attribute Recognition, AAAI-2019Qiaozhe Li*; Xin Zhao; Ran He; KAIQI HUANG, Visual-semantic Graph Reasoning for Pedestrian Attribute Recognition, AAAI-2019Li, Dangwei, Zhang Zhang, Xiaotang Chen, and Kaiqi Huang. "A richly annotated pedestrian dataset for person retrieval in real surveillance scenarios." IEEE transactions on image processing 28, no. 4 (2019): 1575-1590.
Year-2018Wang, Wenguan, et al. "Attentive fashion grammar network for fashion landmark detection and clothing category classification." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018. [Paper]Li, Dangwei, Xiaotang Chen, Zhang Zhang, and Kaiqi Huang. "Pose Guided Deep Model for Pedestrian Attribute Recognition in Surveillance Scenarios." In 2018 IEEE International Conference on Multimedia and Expo (ICME), pp. 1-6. IEEE, 2018. Paper: http://dangweili.github.io/misc/pdfs/icme18.pdfChen, Tianshui, Zhouxia Wang, Guanbin Li, and Liang Lin. "Recurrent Attentional Reinforcement Learning for Multi-label Image Recognition." AAAI2018 Paper: http://www.linliang.net/wp-content/uploads/2018/01/AAAI2018_AttentionRL.pdfPark, Seyoung, Bruce Xiaohan Nie, and Song-Chun Zhu. "Attribute and-or grammar for joint parsing of human pose, parts and attributes." IEEE transactions on pattern analysis and machine intelligence 40, no. 7 (2018): 1555-1569.Zhao, Xin, Liufang Sang, Guiguang Ding, Yuchen Guo, and Xiaoming Jin. "Grouping Attribute Recognition for Pedestrian with Joint Recurrent Learning." In IJCAI, pp. 3177-3183. 2018. Paper:https://www.ijcai.org/proceedings/2018/0441.pdf Code:https://github.com/slf12/GRLModelSarafianos, Nikolaos, Theodoros Giannakopoulos, Christophoros Nikou, and Ioannis A. Kakadiaris. "Curriculum learning of visual attribute clusters for multi-task classification." Pattern Recognition 80 (2018): 94-108.Sarafianos, Nikolaos, Xiang Xu, and Ioannis A. Kakadiaris. "Deep Imbalanced Attribute Classification using Visual Attention Aggregation." In Proceedings of the European Conference on Computer Vision (ECCV), pp. 680-697. 2018. Paper: http://openaccess.thecvf.com/content_ECCV_2018/papers/Nikolaos_Sarafianos_Deep_Imbalanced_Attribute_ECCV_2018_paper.pdf Code: https://github.com/cvcode18/imbalanced_learningLiu, Hao, Jingjing Wu, Jianguo Jiang, Meibin Qi, and Ren Bo. "Sequence-based Person Attribute Recognition with Joint CTC-Attention Model." arXiv preprint arXiv:1811.08115 (2018).Liu, P., Liu, X., Yan, J., & Shao, J. (2018). Localization guided learning for pedestrian attribute recognition. arXiv preprint arXiv:1808.09102. BMVC-paper
Year-2017Fabbri, Matteo, Simone Calderara, and Rita Cucchiara. "Generative adversarial models for people attribute recognition in surveillance." In Advanced Video and Signal Based Surveillance (AVSS), 2017 14th IEEE International Conference on, pp. 1-6. IEEE, 2017.Guo, Qi, Ce Zhu, Zhiqiang Xia, Zhengtao Wang, and Yipeng Liu. "Attribute-controlled face photo synthesis from simple line drawing." In Image Processing (ICIP), 2017 IEEE International Conference on, pp. 2946-2950. IEEE, 2017. PaperHand, Emily M., and Rama Chellappa. "Attributes for Improved Attributes: A Multi-Task Network Utilizing Implicit and Explicit Relationships for Facial Attribute Classification." In AAAI, pp. 4068-4074大佬们都在玩{精选官网网址: www.vip333.Co }值得信任的品牌平台!. 2017.Wang, Jingya, Xiatian Zhu, Shaogang Gong, and Wei Li. "Attribute Recognition by Joint Recurrent Learning of Context and Correlation." In Computer Vision (ICCV), 2017 IEEE International Conference on, pp. 531-540. IEEE, 2017.Wang, Z., Chen, T., Li, G., Xu, R., & Lin, L. (2017, October). Multi-label Image Recognition by Recurrently Discovering Attentional Regions. In Computer Vision (ICCV), 2017 IEEE International Conference on (pp. 464-472). IEEE. Paper: http://openaccess.thecvf.com/content_ICCV_2017/papers/Wang_Multi-Label_Image_Recognition_ICCV_2017_paper.pdf Code: https://github.com/James-Yip/AttentionImageClassTrigeorgis, George, Konstantinos Bousmalis, Stefanos Zafeiriou, and Björn W. Schuller. "A deep matrix factorization method for learning attribute representations." IEEE transactions on pattern analysis and machine intelligence 39, no. 3 (2017): 417-429.
Year-2016Li, Dangwei, Zhang Zhang, Xiaotang Chen, Haibin Ling, and Kaiqi Huang. "A richly annotated dataset for pedestrian attribute recognition." arXiv preprint arXiv:1603.07054 (2016).Yan, Xinchen, Jimei Yang, Kihyuk Sohn, and Honglak Lee. "Attribute2image: Conditional image generation from visual attributes." In European Conference on Computer Vision, pp. 776-791. Springer, Cham, 2016.Li, Yining, Chen Huang, Chen Change Loy, and Xiaoou Tang. "Human attribute recognition by deep hierarchical contexts." In European Conference on Computer Vision, pp. 684-700. Springer, Cham, 2016.Yang, L. , Zhu, L. , Wei, Y. , Liang, S. , & Tan, P. . (2016). Attribute recognition from adaptive parts.Wang, Jiang, Yi Yang, Junhua Mao, Zhiheng Huang, Chang Huang, and Wei Xu. "Cnn-rnn: A unified framework for multi-label image classification." In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 2285-2294. 2016.Fouhey, David F., Abhinav Gupta, and Andrew Zisserman. "3D shape attributes." In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1516-1524. 2016.Wang, Jing, Yu Cheng, and Rogerio Schmidt Feris. "Walk and learn: Facial attribute representation learning from egocentric video and contextual data." In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 2295-2304. 2016.Pedestrian Attribute Detection using CNN, Standford University, CS231n, 2016, Agrim Gupta and Jayanth Ramesh, Paper: http://cs231n.stanford.edu/reports/2016/pdfs/255_Report.pdfSudowe, Patrick, and Bastian Leibe. "PatchIt: Self-Supervised Network Weight Initialization for Fine-grained Recognition" In BMVC. 2016.Liu, Ziwei, Ping Luo, Shi Qiu, Xiaogang Wang, and Xiaoou Tang. "Deepfashion: Powering robust clothes recognition and retrieval with rich annotations." In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1096-1104. 2016.
环境感知作为自动驾驶车辆实现自主行驶的基础和前提,通过对环境信息和车内信息的采集、处理与分析,最终得到车辆周边三维空间中全景分割结果。
行人检测技术作为环境感知中的重要组成部分,在路径规划和智能避障方面发挥着重要作用。
一、什么是自动驾驶行人检测技术
行人检测技术是利用计算机视觉技术判断图像或者视频序列中是否存在行人并给予精确定位。
二、行人检测的难点
l 外观差异大。包括视觉、姿态、服饰和附着物、光照、成像距离等。行人不同的运动姿态、角度,都会显示出不同的外观,而且成像距离远近不一,也会造成外观大小不同。
l 会出现遮挡问题,在行人密集的地方,会发生行人被遮挡的问题,或者是被周围的建筑物遮挡住。
l 背景复杂,有些物体的外观、造型、颜色、纹理等会比较接近人体,例如雕塑或人像广告牌、假人等。
l 检测速度,行人检测一般使用了比较复杂的模型,运算量相当大,要达到实时非常困难,需要进行大量的优化。
三、行人数据标注的主要类型和标注规则
行人检测是监督学习任务,模型训练需要行人在图像中的分类和位置信息,首先对行人信息进行标注,然后用标注信息训练目标检测模型。
1. 主要类型
l Pedestrian:行人(站立),路边的人,坐着的人,蹲着的人或弯腰的人。
l Rider:二轮车骑行者,骑摩托⻋/大电动⻋的人,骑自行⻋的人。
l PersonSitting:坐着的人,蹲着的人或弯腰的人。
l MotorCyclist:骑摩托⻋/大电动⻋的人。
l BiCyclist:骑自行⻋的人。
2. 标注规则
2D拉框:
l 物体大小要求:标注短边大于10像素且长边大于20像素的物体。
l 遮挡截断要求:标注遮挡小于75%的物体。
l 对于行人头部以下被遮挡、不完整的行人,要预测其真实大小。由于行人行走于地面,则边框从头部延伸至地面。
3D拉框:
l 3D框内需要包含目标主体所有点云,不可漏点,但不应包含噪点。
l 若目标物体边界清晰,则3D框边界距离目标主体真实边界最多不能大于10cm。
l 如目标因扫描不全而导致点云缺失,需根据标尺功能辅助与图像中主体的实际关系来脑补缺失面边界。
l 行人距离过近时,行人框可能有一定程度的重叠,此时正常标注即可。
l 行人若携带小物体,比如雨伞、背包等情况,行人的3D框需要包含这些小物体。
l 要注意三视图是否贴合;注意正前方方向是否正确。
l 所有地面上的目标物体其3D标注框底部须贴合地面,不能高于地面或低于地面。
l 当目标距离过远导致目标所在区域点云稀疏、没有地面点或者难以确定3D框下底面高度的情况时,可参考最近的地面点云线的高度和点云中距离最近的3D框来确定大致高度。
l 对于不能准确估计旋转⻆度的行人,旋转⻆度误差标准适当放宽。
3. 注意事项
l 不遗漏框,不误标框,不多标框
l 车上的人需要单独标注,如二轮车三轮车骑手、四轮车的司机、站在货车车厢上的人等都需要单独标注;但点云中若车内人的框完全在车的点云框内,车内人的框不用单独框出来。
l 人携带物(人打伞 ,人拉行李箱等)只标人的主体部分;人抱小孩,连小孩一起标一个框;人拉小孩,人和小孩两个框。
l 人坐在轮椅上,只标人,不标轮椅。人坐在轮椅/婴儿车上,能看到明显的人的就标人,不用标车,从轮椅/婴儿车后面看不清人的就标注车为未知车辆。
景联文科技|AI基础数据服务|数据采集|数据标注|假指纹制作|指纹防伪算法
助力人工智能技术加速数字经济相关产业质量变革,赋能传统产业智能化转型升级
著作权归景联文科技所有,商业转载请联系景联文科技获得授权,非商业转载请注明出处。
点击下方卡片,关注“FightingCV”公众号
回复“AI”即可获得超100G人工智能的教程
点击进入→FightingCV交流群
转载丨极市平台
数据集下载地址:https://sourl.cn/4VK3Bn
SCUT FIR Pedestrian Datasets 是一个大型远红外行人检测数据集。它由大约 11 小时长的图像序列(帧)组成,速度为 25 Hz,以低于 80 km/h 的速度在不同的交通场景中行驶。图像序列来自中国广州市中心、郊区、高速公路和校园 4 种场景下的 11 个路段。该数据集注释了 211,011 帧,总共 477,907 个边界框,围绕 7,659 个独特的行人。
数据集下载地址:https://sourl.cn/mgxHEY
包含 4,372 张图像和 151 万条注释的综合数据集。与现有数据集相比,所提出的数据集是在各种不同的场景和环境条件下收集的。此外,该数据集提供了相对丰富的注释集,如点、近似边界框、模糊级别等。
数据集下载地址:https://sourl.cn/W3Tm2J
Crowd Instance-level Human Parsing (CIHP) 数据集包含 38,280 张多人图像,这些图像具有精细的注释、高外观可变性和复杂性。该数据集可用于人体部分分割任务。
数据集下载地址:https://sourl.cn/XFJDCh
人群数据集是从各种来源获得的,例如 UCF 和数据驱动的人群数据集,以评估所提出的框架。序列多样,代表了朝圣、车站、马拉松、集会和体育场等各种场景中公共空间的密集人群。此外,这些序列具有不同的视野、分辨率,并表现出多种运动行为,涵盖了明显和微妙的不稳定性。
数据集下载地址:https://sourl.cn/wfd7wD
一个用于人群计数的新数据集,该数据集由中国不同位置的大约 2000 个带注释的图像令牌组成,每个图像对应一个 1 秒的音频剪辑和一个密度图。图像处于不同的照明条件下。
数据集下载地址:http://c.nxw.so/9LYoK
该数据集包含极其密集人群的图像。图像主要是从 FLICKR 收集的。
数据集下载地址:http://c.nxw.so/c1PV9
该数据集包含 1,280 张图像和 16,795 个标记的行人,用于人群分析。该数据集使用 720 张图像进行训练,使用 560 张图像进行测试。
名为 frame 的文件夹包含人群图像。
名为 ground_truth 的文件夹包含ground_truth。例如,'1-20170325134657.jpg'对应于'1-20170325134657.mat',以及这张图片中第i个人的真实位置,其中每一行是位置[x,y]
往期回顾
基础知识
【CV知识点汇总与解析】|损失函数篇
【CV知识点汇总与解析】|激活函数篇
【CV知识点汇总与解析】| optimizer和学习率篇
【CV知识点汇总与解析】| 正则化篇
【CV知识点汇总与解析】| 参数初始化篇
最新论文解析
See Finer, See More!腾讯&上交提出IVT,越看越精细,进行精细全面的跨模态对比!
MM2022|兼具低级和高级表征,百度提出利用显式高级语义增强视频文本检索
MM2022 | 用StyleGAN进行数据增强,真的太好用了
MM2022 | 在特征空间中的多模态数据增强方法
ECCV2022|港中文MM Lab证明Frozen的CLIP 模型是高效视频学习者
ECCV2022|只能11%的参数就能优于Swin,微软提出快速预训练蒸馏方法TinyViT
CVPR2022|比VinVL快一万倍!人大提出交互协同的双流视觉语言预训练模型COTS,又快又好!
CVPR2022 Oral|通过多尺度token聚合分流自注意力,代码已开源
CVPR Oral | 谷歌&斯坦福(李飞飞组)提出TIRG,用组合的文本和图像来进行图像检索
点击下方卡片,关注“FightingCV”公众号
回复“AI”即可获得超100G人工智能的教程
点击进入→FightingCV交流群
转载 |专知

行人重识别(PersonReGIdentification,简称 ReGID)旨在研究多个不相交摄像头间特定行人的匹配问题.文中首次以 复杂场景中需要克服的挑战为行人重识别论文的分类依据,将2010-2021年期间发表的研究成果分为7类,即姿势问题、遮挡 问题、照明问题、视角问题、背景问题、分辨率问题以及开放性问题,该分类方式有利于研究人员从实际需求出发,根据要解决的 问题找到相应的解决方案.首先回顾行人重识别的研究背景、意义及研究现状,总结当前主流的行人重识别框架,统计了2013 年以来发表在三大计算机视觉顶级会议 CVPR,ICCV 以及 ECCV 的论文情况和国家基金项目中 ReGID 的相关项目情况; 其次就复杂场景中面临的七大挑战,分别从问题成因和解决方案两方面对现有文献展开分析,归纳总结出处理各类挑战的主流方 法;然后给出了行人重识别研究中泛化性较高的方法,并列举了当前行人重识别研究的难点;最后讨论了行人重识别未来的发 展趋势.
https://www.jsjkx.com/CN/10.11896/jsjkx.211200207
引言
行人重识别是计算机视觉领域的研究热点之一,旨在研 究不重叠的多个摄像区域间对于特定行人的匹配准确率,是 图像检索的子问题[1],多应用于安防和刑侦.我国实现的视 频监控“天网”,就是通过在人流量大的公共区域密集安装监 控设备来实现“平安城市”建设.尽管部分摄像头可转动,但 仍存在监 控 盲 区 和 死 角 等 局 限 性 问 题,ReGID 技 术 弥 补 了摄像设备的视觉局限性.然而,在实际应用中,异时异地相同 行人的图像数据,在姿势、前景背景、光线视角以及成像分辨 率等方面差异较大,使得 ReGID研究具有挑战性. 图1给出了 ReGID 技术框架,描绘了 ReGID 的实现流程 和关键技术.ReGID 技术主要包括特征提取和相似度度量, 具体为:对监控视频帧进行检测和剪裁操作形成候选集,再与 待检索行人 图 像 进 行 对 比,最 后 根 据 相 似 度 排 序 得 到 匹 配 结果.

计算机视觉的热点问题主要有图像分割[2G4]、动作识别与 姿势估计[5G9]、目标检测跟踪[10G13]、人脸技术[14G16]和 ReGID等. ReGID技术的研究工作的开展时间较早,1996年 Cai等[17]首 次开展了相关研究.传统 ReGID方法对行人衣着色块及形状 等视觉特征进行手工标注,将标注好的图像通过距离度量学 习[18]得到行人相似度排序,其检索效率低下且人 工 成 本 较 高.随着深度学习在图像领域的不断发展,2014年起,大量 的科研人员将深度学 习 应 用 到 ReGID 中,实 现 了 更 深 层 次 的特征提取和更有效的 度 量 学 习 算 法[19].为 了 提 高 准 确 率,ReGID工作主要针对 两 方 面 进 行:1)针 对 图 像,提 取 更 具有代表性的特征 表 示;2)针 对 距 离,设 计 更 有 效 的 度 量 学习方法.
近年来,在各种国际顶级会议中 ReGID 相关研究论文的 收录数量较多,图2统计了2013年以来发表在三大计算机视 觉顶级会议 CVPR,ICCV 以及 ECCV 的论文情况.

图3给出了2013年以来国家基金项目中 ReGID 项目的 数量变化情况,其整体呈上升趋势.日益增长的 ReGID 项目 数量带来了该技术的激烈竞争,促进了 ReGID技术的发展;国 家基金的资助是科研工作的保障,也促使 ReGID 研究受到越 来越多的关注.
深度学习的引入使 ReGID 的准确率有较大提升,但应用 场景的复杂性及特殊性等仍是 ReGID技术的瓶颈.本文从另 一个角度分析了复杂场景下 ReGID 所面临的问题和挑战,并 简析了各类问题形成的原因,最后总结了各类问题主流的解 决方法,并 给 出 了 未 来 可 行 的 研 究 方 向.本 文 的 主 要 贡 献 如下:
(1)首次以复杂场景中存在的实际挑战为分类依据,将 2010-2021年期间发表的 ReGID 论文按问题主导类型进行分类, 主要包括行人姿势变化、目标遮挡、照明差异、视角差 异、背景变化、图像分辨率差异以及开放性问题,如图4所示.
(2)通过对文献提出的模型进行归纳,总结出对应的解决 每一类挑战的主流解决方案,便于研究人员从实际需求出发, 根据要解决的问题在本文中快速地找到相应的解决方案,并 在现有研究成果上进行更深入的研究.
(3)总结了可同时用于解决多个 ReGID 挑战的泛化性方 法.ReGID在实际应用中遇到的问题通常不是相互独立的, 复杂场景下往往会遇到多重挑战.经过对大量综述文章的阅 读,我们总结出了一些现存的泛化性方法,这些方法在解决特 定挑战的同时可以一定程度地帮助解决其他挑战.
(4)最后总结了研究中目前尚未解决的难点和未来的发 展方向,如跨域 ReGID问题等.

2.行人重识别的困难与挑战
行人数据来源于异时异地的不同设备,存在不同程度的 行人姿势变化、目标遮挡、照明差异、视角差异、背景变化、设 备像素差异以及开放性问题等,给 ReGID 研究带来了巨大的 挑战.下文简析 ReGID领域出现以上挑战的原因.(1)姿势变化问题. 由于同一行人多张图片存在拍摄时 间差,而且行人在不间断地运动,导致多张同一行人图像数据 间存在姿势差异.(2) 目标遮挡问题. 摄像镜头与目标行人之间存在障碍 物,导致目标 行 人 在 照 片 或 视 频 中 表 现 出 身 体 局 部 缺 失 的 问题.(3)照明变化问题.由于多张行人图像的拍摄时间和地 点不同、拍摄设备对颜色的敏感度不同,因此会出现天色明暗 变化和照明差异等,导致行人图像的色彩差异大.(4)视角变化问题.由于摄像设备架设的高度不统一、摄 像头可以进行一定角度的旋转等,导致行人图像的拍摄视角 出现垂直方向上从平视到俯视的不同、水平方向上从正视到 侧视的不同.(5)背景问题. 不同摄像设备架设的地理位置不同,导致 拍摄到的行人图像背景有差异;同一台摄像设备偏转不同角 度拍摄,同样会导致图像的背景差异;除此之外,两张图像拍 摄时光照、天气不同也会造成图像背景的差异性.(6)分辨率问题. 不同摄像设备像素差异导致拍摄的行 人图像分辨率不同;相同摄像设备架设高度不同也会影响分 辨率,例如架设高则拍摄范围大,在成像中越靠近边缘位置的 目标越小,经剪裁放大后分辨率越低.(7)开放性问题. 开放性问题主要包括除以上6个主要 影响外的其他相关小问题,如服装更换的问题、黑衣人问题以 及数据问题等.对于在服装问题上进行的 ReGID 研究,在实 验阶段默认行人短期服装不变,实际应用中 ReGID 所采集的 数据源一般时间跨度较大,行人服装会产生较大变化且深色 衣物较难进行特征提取;较新颖的 ReGID 研究点被提出时存 在数据集中数据量不足、大量数据标注错误,以及标准数据集 中数据类型不足以满足特殊问题的实验开展等问题.
3.泛化性方法
ReGID在实际应用中遇到的问题通常不是相互独立的, 复杂场景下的 ReGID工作会遇到多重挑战.经过对大量综述 文章的阅读,我们总结出了一些现存的研究方法,可以同时解 决多领域下的问题.本文总结了可以同时解决 ReGID 面临的 多个挑战的方法,如表1所列.

由表1可知,ReGID 中着手解决实际挑战的研究主要集 中在姿势和遮挡问题中,对不同分辨率问题的研究较少.其 主要原因在于,标准数据集来自同一批架设的同配置相机,同 一数据集中较少有不同分辨率的图像.
4 未来研究方向
本文 从 实 际 应 用 出 发,开 展 对 ReGID 的 研 究.我 们 将 ReGID实际应用中会遇到的挑战分为以下几类:首先从行人 自然姿态的不同和检测算法精度差异两个角度介绍了 ReGID 的姿态问题;其次根据固定遮挡和前景遮挡两种不同的遮挡 方式介绍了 ReGID的遮挡问题;然后针对不同照明和多模态 相机两种常 见 问 题 介 绍 了 ReGID 的 照 明 问 题;最 后 从 角 度问题、背景问题和分辨率问题3个方面来介绍 ReGID 的不同 处理方式.除此之外,近年来发表了许多新颖且重要的论题, 我们在开放性问题中进行了讨论. 近年来 ReGID技术发展迅速,在实验阶段取得了不错的 学术成果,但仍存在一些在挑战有待进一步的研究.
(1) 数据集.ReGID 技术在几个大规模的标准数据集上 取得了阶段性成果,但是仍存在一些在标准数据集上无法处 理的问题,例如针对换衣场景、真实多源场景等问题的研究方 法存在没有标准数据集、实验数据的比对针对性不强的问题. 因此,在真实多源任务的标准数据集上数据的收集和创建问 题亟待解决.
(2) 数据标注.对 ReGID 的样本标注是一个开销较大的 任务,在实验中应该尽量使用少量标注或无标注的样本学习 网络模型.在 未 来 的 研 究 中,基 于 半 监 督 或 无 监 督 学 习 的 ReGID研究是一项工作重点.
(3) 跨域识别.在实际应用的 ReGID场景中,需要同时处 理多个实验阶段的单一挑战域,例如不同分辨率常见于不同 批次架设的镜头、时间地点的改变导致光照和环境不同等问 题同时存在且常见.ReGID系统需具备应对多挑战的自动处 理机制,这是未来研究须解决的问题.
(4)复杂场景识别.嫌疑人往往选择夜间照明条件不好 的时间点或有明显遮挡物的地点出行,以试图躲避被拍摄. 若要将 ReGID方法应用到刑侦中,复杂场景下的 ReGID 是未 来要解决的问题.
(5)合成图像与真实图像之间的差异性问题.目前 ReG ID中对于数据集不足的解决方法之一是使用合成图像,合成 图像在一定程度上可以解决特定问题,但是由于合成图像有 意规避了干扰因素,因此其不足以替代实际应用中的真实图 像.使用合成图像时应该进行相应的预处理工作,以弥补与 真实行人图像之间的差异.
(6)模型自动更新.ReGID的算法模型层出不穷,针对每 一类挑战的网络模型往往有较多的相似之处,应该做到低成 本高效率的 ReGID,例如微调现存网络模型,使其能应用到新 的拍摄场景,或利用新数据优化之前的模型等. 结束语 本文围绕行 ReGID 在实际应用中会遇到的问 题,梳理了2010G2021年 ReGID方面的主要研究,针对实际应 用中遇到的问题进行分类,介绍了每种类型的问题及现有解 决方案,继而总结了解决多挑战问题的方法,最后讨论了 ReG ID未来的研究方向.综上,本文对复杂场景中存在的实际挑 战作为分类依据的 ReGID 进行了综述,有望为未来 ReGID 系 统的深入研究提供重要指导.
往期回顾
基础知识
【CV知识点汇总与解析】|损失函数篇
【CV知识点汇总与解析】|激活函数篇
【CV知识点汇总与解析】| optimizer和学习率篇
【CV知识点汇总与解析】| 正则化篇
【CV知识点汇总与解析】| 参数初始化篇
【CV知识点汇总与解析】| 卷积和池化篇 (超多图警告)
最新论文解析
如何训练用于图像检索的Vision Transformer?Facebook研究员解决了这个问题!
ICLR22 Workshop | 用两个模型解决一个任务,意大利学者提出维基百科上的高效检索模型
See Finer, See More!腾讯&上交提出IVT,越看越精细,进行精细全面的跨模态对比!
MM2022|兼具低级和高级表征,百度提出利用显式高级语义增强视频文本检索
MM2022 | 用StyleGAN进行数据增强,真的太好用了
MM2022 | 在特征空间中的多模态数据增强方法
ECCV2022|港中文MM Lab证明Frozen的CLIP 模型是高效视频学习者
ECCV2022|只能11%的参数就能优于Swin,微软提出快速预训练蒸馏方法TinyViT
CVPR2022|比VinVL快一万倍!人大提出交互协同的双流视觉语言预训练模型COTS,又快又好!
CVPR2022 Oral|通过多尺度token聚合分流自注意力,代码已开源
CVPR Oral | 谷歌&斯坦福(李飞飞组)提出TIRG,用组合的文本和图像来进行图像检索



 haar行人检测结果
haar行人检测结果 hog行人检测结果haar人脸检测结果
hog行人检测结果haar人脸检测结果


















留言0